L'immagine numerica.
Il processo di informatizzazione ha riguardato molteplici discipline e campi d’applicazione, la fotogrammetria non fa certo eccezione, anzi è uno degli ambiti operativi che più si sono avvantaggiati delle nuove tecniche e metodologie. Tale evoluzione si è tradotta anche in una diversa rappresentazione del dato primario –l’immagine–, se nel passato erano richiesti tempi, anche tecnici, per la sua produzione, metodi di conservazione costosi, oggi, con l’immagine digitale abbiamo un supporto immutabile sia dal punto di vista metrico che radiometrico, con tutti i vantaggi connessi alla conservazione digitale e gestione. In termini analitici l’immagine numerica è fondamentalmente una matrice di elementi quadrati, i pixel, il cui contenuto radiometrico è espresso da una funzione discreta g(i,j), dove i,j sono dei numeri interi che rappresentano la posizione in riga e colonna dell’elemento all’interno della matrice. Difatti nella realtà qualunque sia il metodo di acquisizione di un’immagine digitale, non sono certamente entità esprimibili in forma chiusa, quindi si ha la necessità di ricercare una relazione discreta che le rappresenti. Per convenzione, nelle immagini digitali, l’origine del sistema righe-colonne è posto nell’angolo in alto a sinistra (Fig. 2.41), ad una distanza di mezzo pixel dallo spigolo dell’immagine, dato che, le misure di posizione sono sempre riferite al baricentro del singolo elemento.
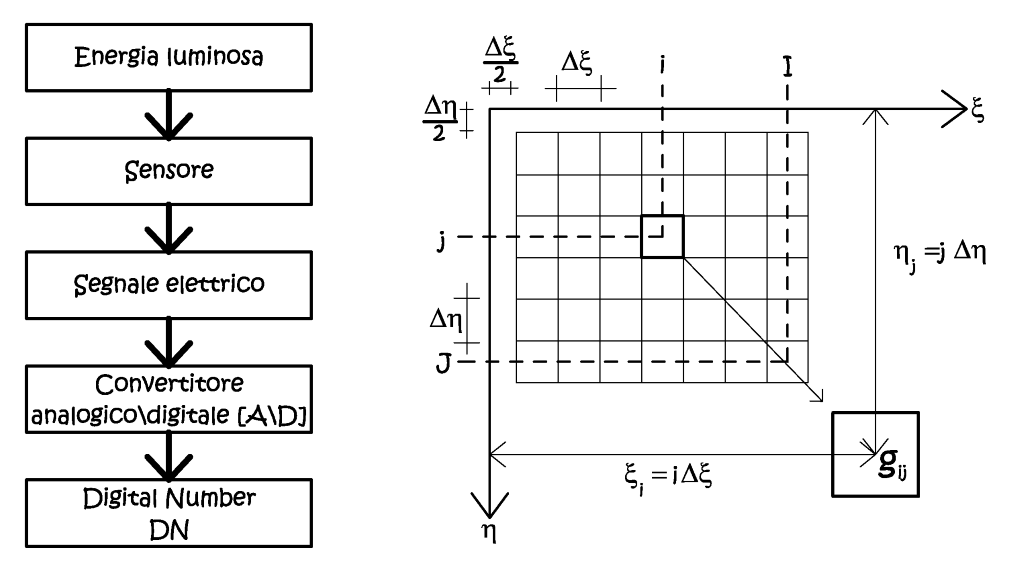
Fig. 2.41 – Processo di generazione di un’immagine digitale e suo sistema di riferimento.
Il processo che è alla base della generazione di una immagine numerica prende il nome di digitalizzazione, ed esso avviene campionando le variabili radiometriche continue, cioè sottoponendole ad un processo di quantizzazione. Alla fine di questo processo si ottiene un valore numerico identificativo di ogni singolo pixel (Digital-Number), cioè la sua risoluzione radiometrica, essa si esprime come un ottetto binario, cioè composto da otto bit (byte). Utilizzando questa metrica si possono esprimere 256 valori singoli (2^8 ), cioè dal valore zero al valore 255. Ad esempio, per un’immagine monocromatica sarebbe sufficiente un DN composto da un singolo bit, mentre con 256 livelli di radianza compresi tra 0 (nero) e 255 (bianco), possiamo avere un’immagine a toni di grigio o a palette di colori. In questo particolare caso l’immagine viene definita a 8bit, dato che questi vengono usati completamente per rappresentare tutti i valori radiometrici possibili.
Se l’immagine digitale deve rappresentare oggetti a colori, si possono usare le note regole della sintesi additiva, nella quale ogni colore è la somma di tre colori fondamentali, la cui diversa saturazione di ognuno può essere rappresentata da un valore a 8bit (0-255); la radiometria di un pixel è quindi fornita dai tre numeri (DN), che esprimono le saturazioni dei tre colori fondamentali, tre byte per ogni pixel, cioè immagini a 24bit. In termini analitici le immagini a colori a tre canali possono essere espresse come dalla “somma” di tre matrici radiometriche, è per questa ragione che si parla di matrice immagine a tre piani.

Altro aspetto caratterizzante le immagini digitali è la loro risoluzione geometrica, che esprime in modo diretto le dimensioni del singolo pixel, ed è collegata alla densità campionamento. La risoluzione esprime il numero di pixel contenuti in una data dimensione, ed essa viene solitamente espressa in dpi (dot per inch), cioè punti per pollice (2,54cm). Un’elevata risoluzione geometrica genera una matrice con un grande numero di righe e colonne, con un conseguente aumento del grado di dettaglio, ma ciò comporta un aumento delle capacità di memorizzazione necessarie ed, in ultima analisi, una maggiore pesatezza computazionale dell’immagine.

In alternativa la risoluzione viene espressa come dimensione d_pix dei singoli pixel, espressa in micrometri [μm].

Nella fotogrammetria aerea e terrestre digitale si usa relazionare le dimensioni del pixel con le corrispettive dimensioni metriche “al suolo” dello stesso, tale parametro in letteratura assume l’acronimo di GSD (Ground Sample Distance):
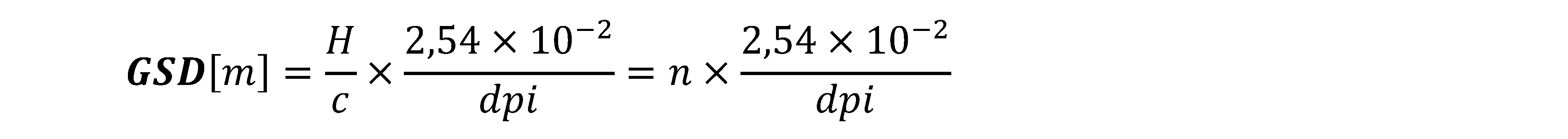
Ove n è il denominatore della scala media del fotogramma, si noti come questa relazione consenta anche una più agevole definizione di quelli che sono i parametri di progetto del volo fotogrammetrico. Anche le immagini digitali possono essere soggette a degrado, sia metrico, che radiometrico, se non vengono utilizzati gli opportuni formati di memorizzazione del dato. Nella fotogrammetria digitale si usano sostanzialmente due formati, il TIFF e il JPEG, il primo è il formato preferito, dato che garantisce una compressione non distruttiva del dato, ed inoltre consente la registrazione di più layers immagine, caratteristica molto apprezzata nei GIS e nei software di restituzione. Il JPEG consente sia di usare una tecnica di compressione lossy, dove abbiamo una certa perdita di informazioni, con diversi gradi, sia una tecnica lossless ove non abbiamo perdite di informazioni, anche se le dimensioni risultati saranno comunque inferiori al corrispettivo formato TIFF. In particolare è sconsigliabile utilizzare rapporti di compressione, nel formato JPEG, superiori a 1/7; oltre tale limite la perdita di informazione radiometrica inizia ad influenzare negativamente il contenuto metrico dell’immagine. Nella tabella seguente si riportano i valori statistici di precisione rilevati da procedure di posizionamento automatiche su diverse immagini, con diversi gradi di compressione; è facile notare come per valori di compressione maggiori di 1/7, si abbia uno scarto quadratico medio troppo elevato, ben superiore alle dimensioni di un singolo pixel, come vederemmo.
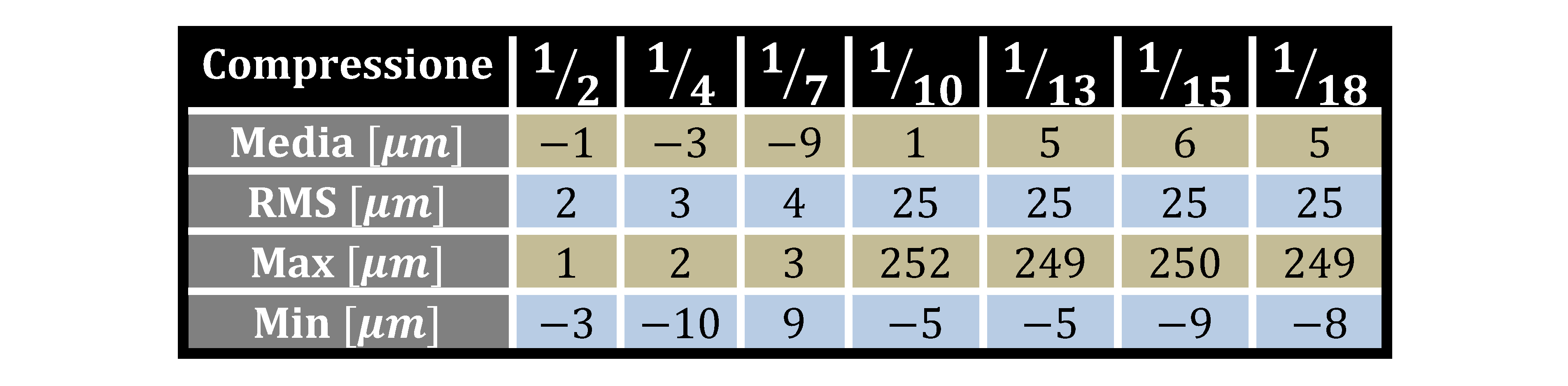
La risoluzione geometrica di una immagine digitale è la minima informazione metrica resa disponibile nella rappresentazione, quello che comunemente viene identificato con il “livello di dettaglio”. La relazione precedente viene usata in sede di progetto del volo, ed essa non è legata alle sole caratteristiche tecniche/geometriche della camera da presa, ma il livello di dettaglio desiderato può essere raggiunto anche agendo sui parametri di volo, in primis la quota.
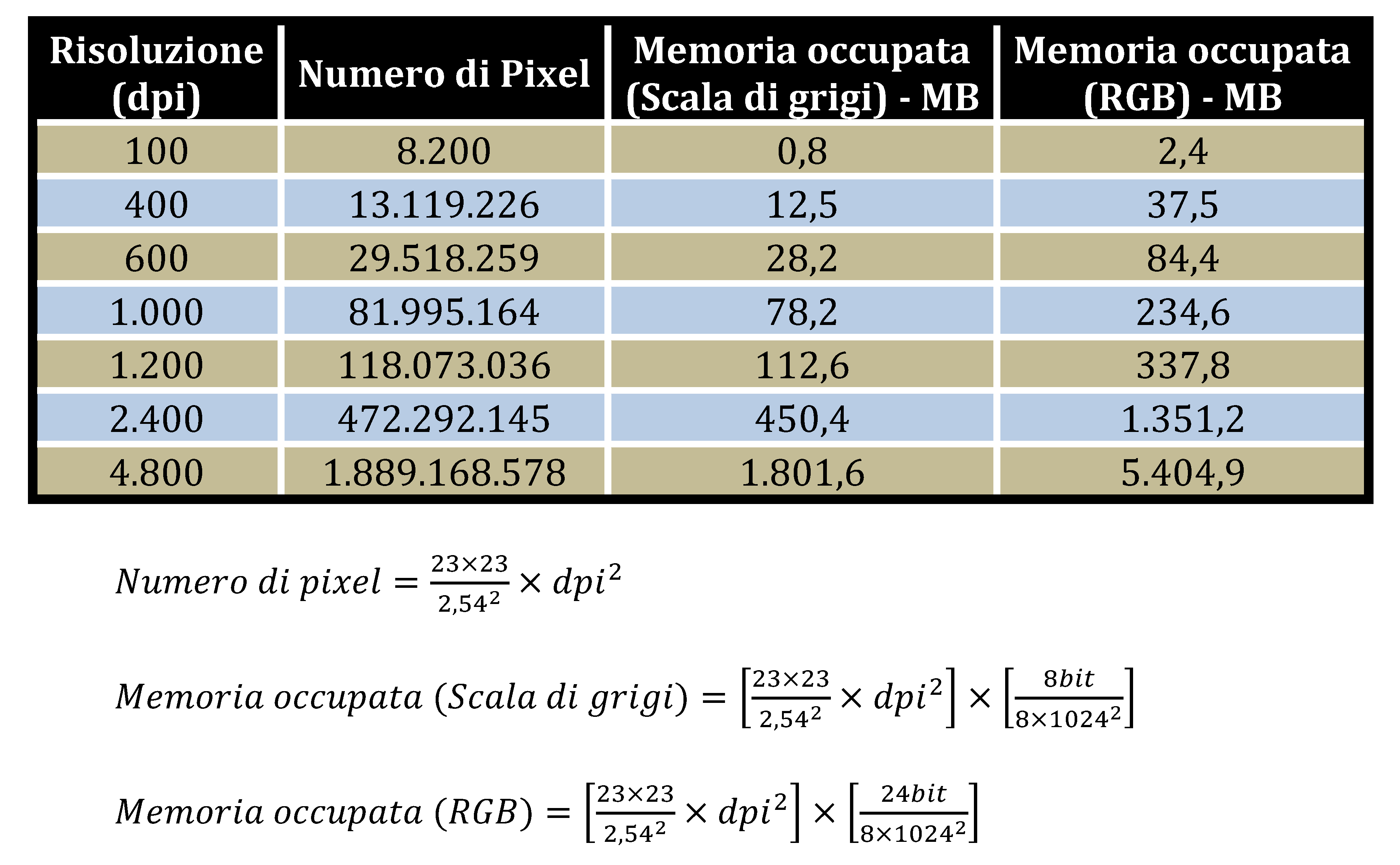
Nella fotogrammetria d’archivio il principale problema è legato all’acquisizione digitale di materiale fotografico già esistente, che nei suoi ultimi sviluppi aveva raggiunto importanti livelli di dettaglio. Ad esempio la grana di una emulsione fotografica molto lenta, di elevatissima qualità, in bianco e nero, può anche raggiungere la dimensione di 4μm, mentre le pellicole a colori hanno una dimensione di grana di 15-25μm. In realtà la risoluzione di un fotografia analogica è misurata in numero di linee per millimetro (lpm), e per garantire un intervallo di campionamento adeguato si è spesso usata la seguente relazione

Ad esempio una buona foto può avere un contenuto informativo di 60÷80lpm che corrisponde ad un ∆D pari a 5μm circa, quindi ad risoluzione di 5.000dpi. Nella fotogrammetria digitale di precisione degli inizi, questo fattore ha sempre rappresentato un problema, sia in termini di costi di gestione, sia dei tempi di elaborazione richiesti da immagini così grandi. Ma anche questo problema è stato superato con la veloce evoluzione tecnica degli apparati utilizzati. Nella tabella che segue è riportata la risoluzione, e lo spazio di occupazione delle immagini non compresse di fotogrammi aerei standard (23×23)cm.
L'acquisizione delle immagini digitali.
Il dato primario è formato, in questo caso, da immagini numeriche, le quali possono essere ottenute utilizzando principalmente due modalità diverse. Si parla di acquisizione diretta quando l’immagine originale è generata dall’impiego di camere da presa digitali, mentre si parlerà di acquisizione indiretta quando l’immagine originale è una fotografia tradizionale, opportunamente digitalizzata. Le due operazioni sono profondamente diverse, sia per i mezzi usati, sia per le successive metodologie di gestione. Mentre la conversione in digitale di fotogrammi analogici è una “traduzione digitale” della fotogrammetria, storicamente intesa, come il metodo atto ad ottenere un’interpretazione metrica ortogonale di un contenuto geometricamente prospettico. Al contrario, nella fotogrammetria ad acquisizione diretta, si possono usare nuovi approcci, anche analitici, dato che i metodi di presa sono diversi, e consentono l’uso di nuove soluzioni.
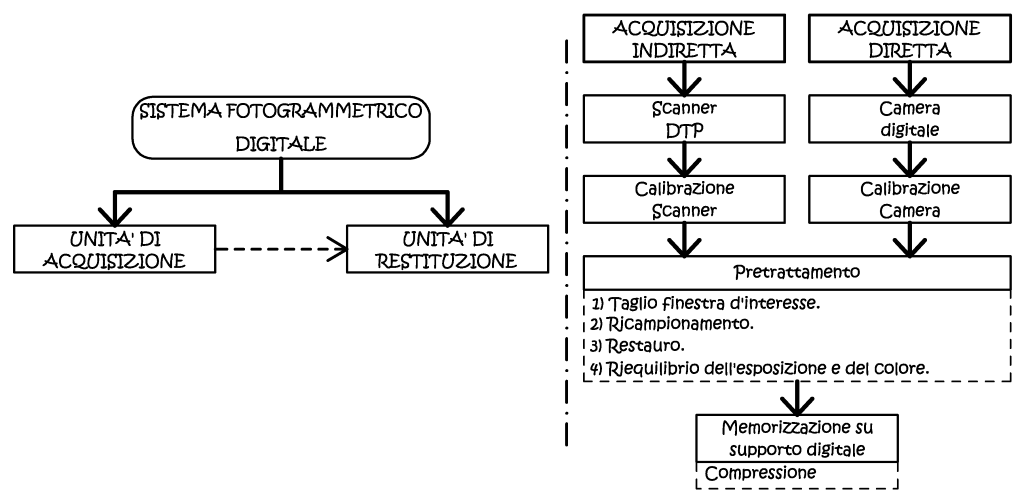
Fig. 2.42 – Schema logico-funzionale del sistema fotogrammetrico digitale e della fase di acquisizione.
L'acquisizione indiretta tramite processo di scansione.
La maggior parte dei fotogrammi digitali utilizzati nel presente studio,
derivano dalla scansione di supporti fotografici canonici, grazie all’utilizzo
di particolari dispositivi di registrazione raster, chiamati scanner (Fig.
2.43). Anche in quest’ambito troviamo dispositivi progettati e pensati
per l’uso fotogrammetrico, dato che devono fornire adeguante caratteristiche
di precisione radiometrica e geometrica, cioè l’esatto posizionamento dei
pixel. Ma si possono trovare anche dispositivi consumer, cioè indirizzati
all’uso generalista, ovviamente il loro costo è nettamente inferiore, anche
di un ordine di grandezza, il loro uso è limitato alla fotogrammetria dei
vicini, con opportune metodologie di calibrazione, ad esempio con reticoli
di controllo e software specialistici.
In base al meccanismo di acquisizione, gli scanner, si posso suddividere
in due categorie: scanner piani, nei quali l’immagine è posta su di un
piano di scansione, e scanner a tamburo rotante, qui la foto è inserita
su un supporto cilindrico, posto in rotazione, durante il processo di scansione.
Per la natura stessa del metodo utilizzato, gli scanner fotogrammetrici
sono scanner piani, gli unici a garantire maggiori prestazioni, ed uno
stress inferiore al materiale fotografico. Nella tabella successiva,
sono riportati i requisiti geometrici e radiometrici richiesti ad uno scanner
fotogrammetrico.

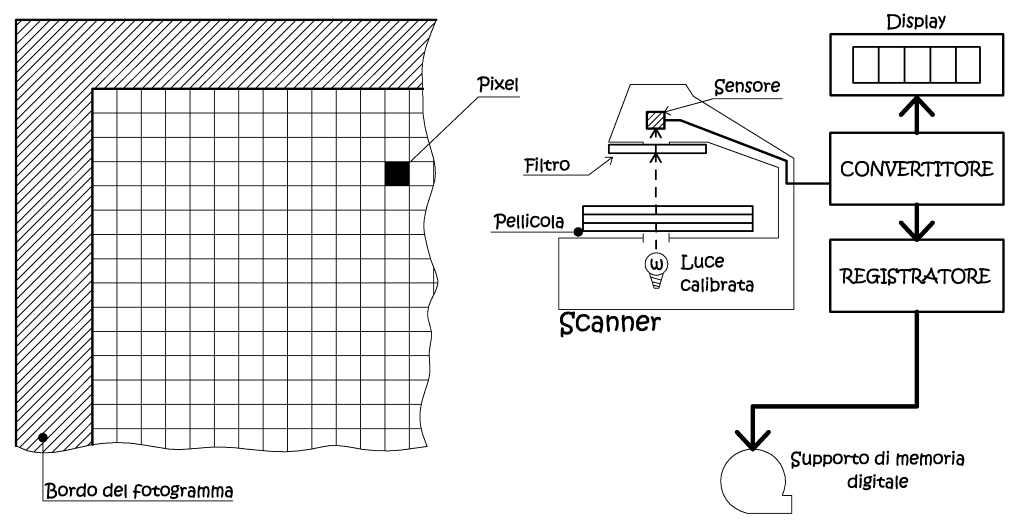
Fig. 2.43 – Schema semplificato di uno scanner fotogrammetrico.
Oltre alle differenze appena riportate, gli scanner fotogrammetrici si distinguono anche per i tre modi di montaggio dei sensori fotosensibili.
• Sensore singolo, che acquisisce il fotogramma per singole linee.
• Fila di sensori, che effettua la scansione per strisce, queste possono
essere due o tre, ad esempio una fila per ogni colore fondamentale (RGB).
• Matrice quadrata di sensori, in questo caso la scansione avviene per
porzioni. Le immagini ottenute vengono riunite numericamente in post-produzione,
a formare il fotogramma completo, grazie all’impiego di un reticolo di
collimazione, i cui nodi (crocicchi), vengono utilizzati come riferimento.
Tra questi tre sistemi il preferito è il secondo, dato che, per i scopi fotogrammetrici fornisce le maggiori risoluzioni geometriche, vista la tipologia di sensore utilizzato. Le maggiori deformazioni geometriche si presentano lungo la direzione di scorrimento del carrello con gli elementi fotosensibili, e non potrebbe essere diversamente, quindi periodicamente lo strumento deve essere controllato, ed eventualmente ricalibrato. Il controllo può essere eseguito direttamente dall’utente, con l’uso di reticoli di calibrazione.
L’acquisizione diretta: camere fotogrammetriche digitali.
Come si è già ribadito, la fotogrammetria digitale sarebbe solo una diversa reinterpretazione di quella classica, se non fosse per l’uso delle camere da presa digitali. La caratteristica principale di queste è di catturare l’immagine in formato numerico e di trasmetterla, e conservarla nel tempo, senza alterazioni. In altri termini la relazione di posizione di un punto sul terreno e la sua immagine, fissata al momento della presa, rimane univocamente definita e immutata nel tempo. L’uso dei sensori elettronici ha consentito maggiori possibilità di captazione elettromagnetica, con la generazione di immagini multispettrali, atte ad essere utilizzate in studi tematici del territorio, oppure, in campo fotogrammetrico, di avere una migliore visibilità nelle zone in ombra, in fase di restituzione. Nelle camere digitali, in generale, il sensore è costituito da un elemento rettangolare o quadrato di silicio, suddiviso in un grigliato che ne individua gli elementi formanti, i pixel. Se questi sono posti a formare un sensore rettangolare o quadrato, esso viene detto di tipo a matrice o, con terminologia anglosassone, di tipo area array. Se i pixel sono posti lungo un’unica linea, siamo nell’ambito dei sensori lineari, o linear array.
Da un punto di vista progettuale si distinguono sensori areali multipli mosaicati (frame based) e sensori lineari pushbroom. I primi hanno il notevole vantaggio di una maggiore maneggevolezza, in quanto i singoli fotogrammi sono gestibili come le scansioni digitali di fotogrammi tradizionali; possono essere di vario tipo, come immagine digitale finale generata attraverso l’assemblaggio digitale di più immagini, o acquisite da obiettivi separati e su più bande spettrali. Anche le camere frame based sono dotate del dispositivo FMC (Forward Motion Compensation), che agisce traslando nella direzione del moto il sensore, similmente a quanto avveniva nelle camere tradizionali, oppure utilizzando un particolare algoritmo elettronico (TDI – Time Delay and Integration), in questo caso vi è un numero massimo di righe sulle quali può essere distribuito l’accumulo progressivo dei fotoni, questo valore prende il nome di maximum FMC capability. Le immagini prodotte dalle camere da sensori quadrati o rettangolari, seguono la proiettività a prospettiva centrale unica, quindi i prodotti possono essere orientanti e restituiti con le medesime tecniche e, basi analitiche, adottate nella fotogrammetria classica. Ma data la difficoltà di ottenere sensori di quel tipo ad elevata risoluzione, ha convinto sempre più tecnici a dotarsi di una tecnica di presa propria delle piattaforme satellitari, cioè di sistemi a prospettiva centrale multipla¸ che utilizzano sensori a “spazzolamento”, o pushbroom. Questi sono composti da una serie di array lineari di elementi CCD, opportunamente assemblati, che abbracciano il campo di presa per porzioni lineari trasversali al moto. Le immagini digitali sono così formate linea per linea, acquisite ad intervalli di tempo regolari, in funzione del tempo di esposizione.
Dal punto di vista geometrico lo schema di riferimento è quello della prospettiva centrale, relativo però non all’intera immagine ma alla singola linea, da cui il nome immagini a prospettiva centrale multipla. Questo implica una continua variazione dei parametri d’orientamento esterno, ovvero posizione del centro di presa ed angoli d’assetto cardanici. Il problema sarà ancora governato dalle equazioni di collinearità, ma i loro parametri saranno dipendenti dal tempo. La flessibilità delle tecniche digitali, anche in termini di miniaturizzazione, ha consentito l’integrazione di più sensori all’interno di un unico corpo macchina, ed in modo del tutto simile alle camere frame based, anche nelle camere pushbroom possiamo avere più sensori montati in modo parallelo, condividenti lo stesso sistema ottico, e sensibili a differenti bande dello spettro (Fig. 2.44). Quindi abbiamo una vista nadirale, una vista inclinata nella direzione del volo (forward), ed una opposta al moto del velivolo (backward).
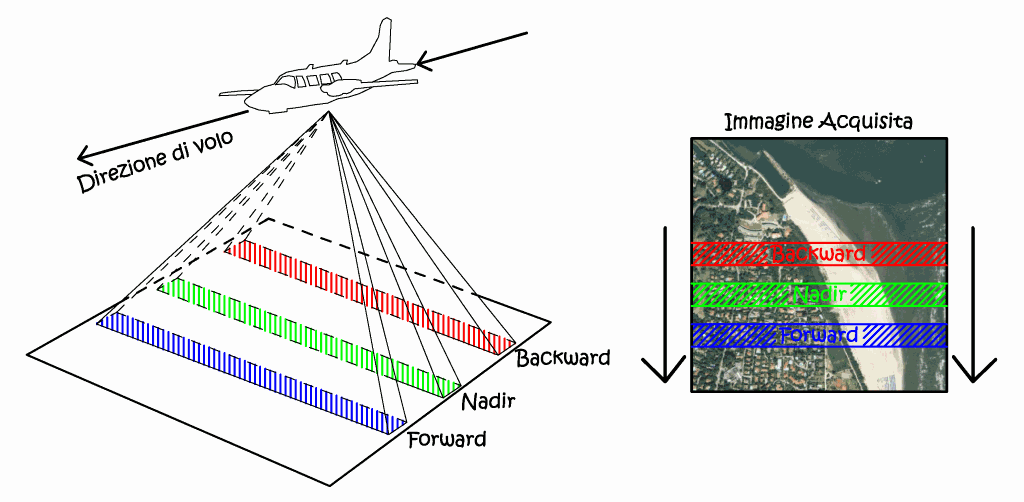
Fig. 2.44 – Schema di acquisizione Pushbroom da piattaforma aerea.
La camera Leica ADS40.
Il fine di questo capitolo è di descrivere uno degli strumenti che più hanno avuto successo nel mercato, soprattutto italiano, ed anche perché una parte dei dati oggetto del presente studio sono stati ottenuti con l’uso di questa camera. La camera ADS40 è presente nel mercato dal 2004, essa monta una serie di sensori lineari multipli, in grado di riprendere il territorio per strisciate continue, eliminando la necessità di utilizzare lo schema dei fotogrammi parzialmente sovrapposti, tutto a vantaggio della precisione, e dei costi operativi legati al minor numero dei punti d’appoggio fotografici. L’ottica della camera è costituita da un obiettivo telecentrico, ad ampio campo, che ha il fine di orientare sul piano focale tutti i raggi uscenti da esso nello spazio immagine. Sul piano focale troviamo un serie di sensori lineari da 12Mpixel, con una dimensione del singolo pixel pari a 6,5μm, posti secondo la seguente configurazione.
• Tre gruppi di due sensori pancromatici, in posizione forward, nadir
e backward; le coppie di sensori sono fra loro sfalsate, in senso trasversale,
di mezzo pixel, in questo modo modulando opportunamente i tempi di integrazione,
è come se avessimo un sensore con una dimensione del singolo pixel pari
a 3,5μm.
• Un gruppo di tre sensori, in posizione nadir, per l’immagine RGB, secondo
le tre componenti.
• Sempre in posizione nadir, un sensore per l’infrarosso vicino,
destinato a studi vegetazionali, e per migliorare la visione delle parti
in ombra.
Conoscendo la dimensione del singolo sensore lineare, pari a 78mm, e la distanza focale, pari a 62mm, consegue un angolo di campo trasversale di 64°, mentre nella direzione del volo, se si considerano la combinazione di tutte le visuali, si hanno 42,6° di campo stereoscopico, un valore addirittura superiore a quello che si ha con le camere fotogrammetriche tradizionali. Con una quota volo di 2.000m la risoluzione geometrica al suolo GSD è pari a 10cm, se si sfrutta la capacità dei sensori pancromatici sfalsati, mentre la frequenza di scansione può variare dalle 200 alle 800 linee al secondo, in ragione della velocità dell’aereomobile.
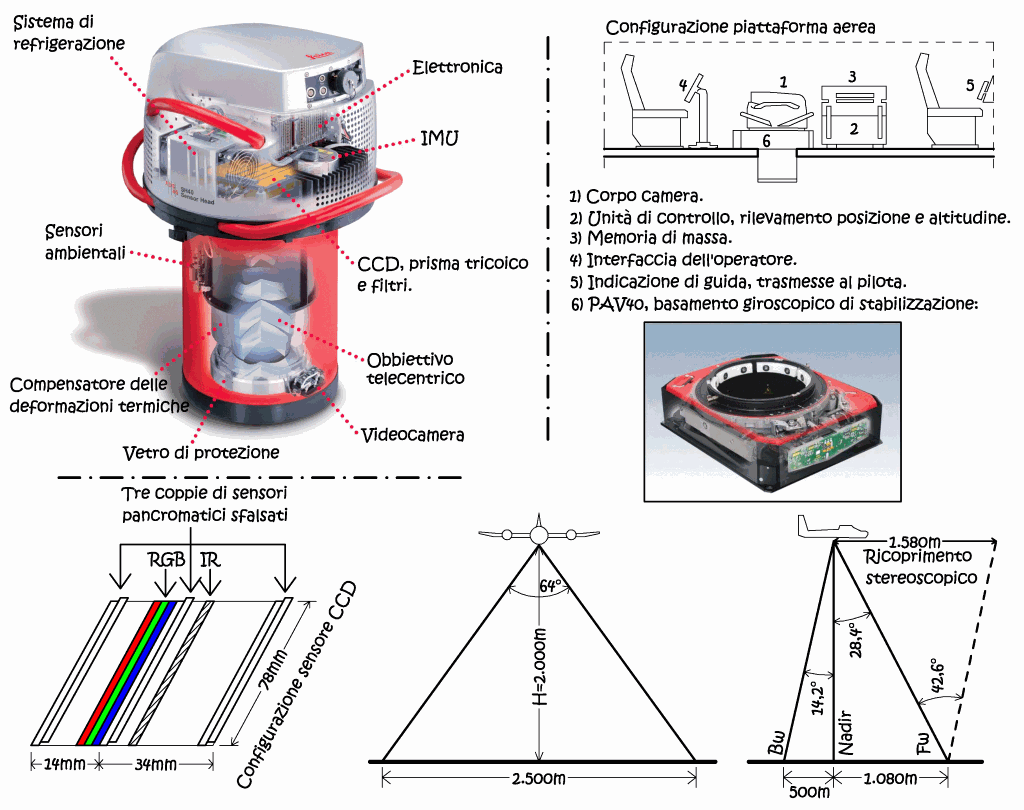
Fig. 2.45 – Schema costruttivo della camera ADS40, disposizione dei sensori lineari sul piano focale, campo di vista trasversale e longitudinale ed angolo di massima stereoscopia; configurazione standard della piattaforma di volo.
Si noti che quello che un tempo veniva eseguito con un periscopio di navigazione, con il continuo controllo ed intervento manuale dell’operatore, tramite il cinederivometro, oggi il sistema è totalmente automatizzato. E questo grazie all’impiego di un dispositivo IMU (Inertial Measurement Unit), cioè una serie di sensori che consentono di rilevare l’orientamento nello spazio della camera, ciò permette di compensare i movimenti accidentali del velivolo, con una modalità di intervento continuativa. Il sistema è integrato con una unità di controllo provvista di interfaccia utente, che fornisce continue informazioni all’operatore sulla posizione, parametri del sensore e condizioni del sistema. Vi è inoltre un monitor a servizio del pilota con messaggi di navigazione, per fornire tutte queste informazioni il sistema prevede l’impiego di un ricevitore GPS, interfacciato con un master a terra (GPS cinematico). I dati vengono conservati in un supporto digitale, nel nostro caso un hard disk da 580GB, che consente ben nove ore di presa.
L’UNITA’ DI RESTITUZIONE.
L’unità di restituzione digitale è composto da un insieme di hardware e software, dalla cui interazione, risulta possibile derivare prodotti fotogrammetrici da immagini digitali, sia utilizzando tecniche manuali che automatiche. Una volta registrate, in formato numerico, le immagini stereoscopiche dello spazio che si intende rilevare, con i metodi che abbiamo visto, è possibile operare tutte le fasi del processo di restituzione in ambiente digitale, attraverso l’uso di specifici software e hardware dedicato. Il software segue delle procedure di calcolo codificate dalla formulazione analitica della proiettività, che conducono alla determinazione delle coordinate tridimensionali dello spazio oggetto. Anche nelle stazioni fotogrammetriche digitali (Digital Photogrammetric Workstation – DWP) è possibile ottenere la visione tridimensionale delle coppie fotogrammetriche, difatti si è passati dalle vecchia tecnica dell’anaglife, ove la visione contemporanea di fotogrammi stereoscopici era ottenuta con l’uso combinato di filtri colore (generalmente rosso e blù), all’uso di tecniche che sfruttano la polarizzazione della radiazione luminosa.
• Con occhiali a polarizzazione attiva.
• Con doppio schermo, specchio polarizzante e occhiali passivi.
Il primo metodo sfrutta la veloce alternanza delle immagini su monitor: la visualizzazione dell’immagine sinistra con l’occhio sinistro, e l’immagine destra con l’occhio destro, viene resa possibile con un paio di occhiali polarizzanti, in sincronia con il refresh rate del monitor, collegati via wireless all’elaboratore. Tale metodo richiede l’uso di monitor ad elevato refresh rate, almeno 120Hz, per consentire una fluida visione a 60Hz per occhio, ciò si è scontrato storicamente con l’introduzione dei monitor LCD, che a differenza della tecnologia analogica CRT non consentono elevate frequenze verticali (tranne alcuni modelli). Quindi si sono introdotti metodi che vedono l’uso del doppio monitor, posti in modo opportuno, le immagini di questi sono osservate dall’operatore attraverso una lamina semiriflettente, posta secondo la bisettrice dell’angolo formato dai monitor medesimi. L’immagine di uno dei due monitor è trasmessa direttamente all’operatore, senza subire variazioni, mentre l’immagine del secondo monitor subisce una riflessione, e pertanto il segnale elettromagnetico associato risulta sfasato di π/2. Osservando le immagini mediante occhiali aventi lenti polarizzate secondo direzioni ortogonali, si può ottenere la visione tridimensionale del modello (o immagine plastica).
L’operatore può esplorare il modello stereoscopico in modo dinamico ed in real time, ricreando una esperienza di realtà aumentata del modello tridimensionale, anche le operazioni di collimazione si avvantaggeranno di questo: difatti, con l’uso del mouse convenzionale si muoverà il puntatore nelle due dimensioni piane, mentre sarà possibile spostarsi nella terza dimensione con l’uso di una trackball. I punti collimati saranno direttamente espressi, in formato digitale, nelle loro coordinate oggetto, senza alcuna riduzione di scala, dato che si opera in uno spazio numerico.
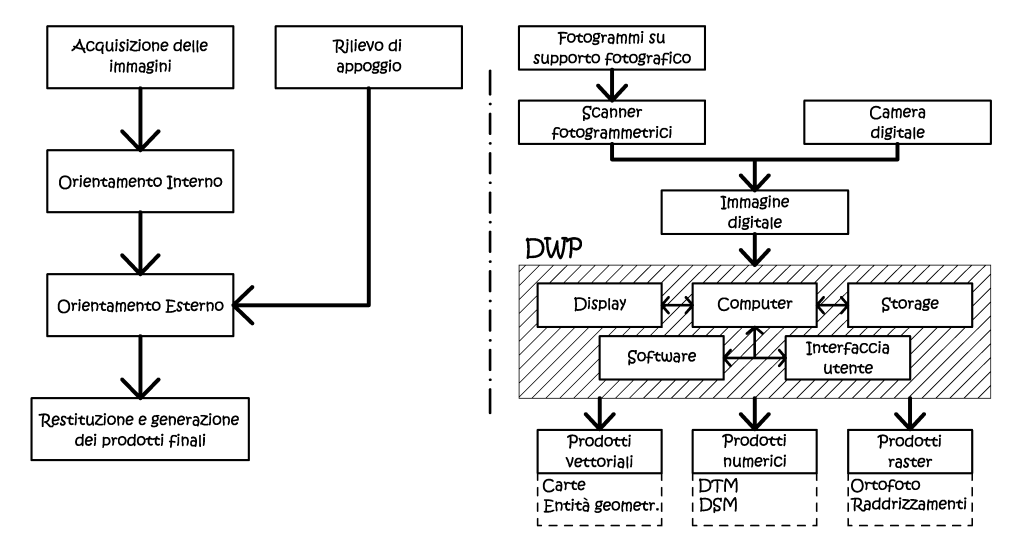
Fig. 2.46 - Schema di un sistema fotogrammetrico digitale; l’area tratteggiata comprende i componenti di una stazione fotogrammetrica digitale.
Le collimazioni stereoscopiche possono essere fatte automaticamente, o almeno supportate dal calcolatore, e le coordinate vengono determinate mediante un procedimento di compensazione ai minimi quadrati. La tecnica digitale ha dato la possibilità di integrare una serie di algoritmi di autocorrelazione, cioè tutte quelle tecniche statistiche che simulano il processo fisico della collimazione stereoscopica, ossia l’individuazione dei punti omologhi. Un bravo restitutista può al massimo collimare con la precisione pari alla dimensione di metà pixel, ebbene, l’autocorrelazione permette di superare questo limite fisico di almeno un ordine di grandezza, consentendo di raggiungere le prestazioni proprie di un restitutore analitico di medie prestazioni. I prodotti della restituzione possono essere di natura vettoriale (carte, elementi vettoriali in genere), di natura numerica, ove le coordinate dei punti oggetto sono registrate con criteri logici, ad esempio con il fine di ottenere modelli tridimensionali di superficie (DSM) o del terreno (DTM), ed infine prodotti raster cioè a contenuto radiometrico come possono essere le immagini rettificate (ortofoto).
GLI ALGORITMI DELLA FOTOGRAMMETRIA DIGITALE.
Il metodo digitale ha tradotto in termini accessibili ai normali utenti, quelle operazioni che altrimenti avrebbero richiesto un eccessivo impegno. Ma non solo, l’esigenza di gestire nuove situazioni, ha necessitato l’introduzione di tecniche e metodi analitici per affrontarle in modo compiuto. Le tecniche possono essere riassunte nei due gruppi seguenti.
• Tecniche di ricampionamento dell’immagine.
• Gli algoritmi di autocorrelazione (Image Matching).
Le prime vano usate quando sia richiesta l’individuazione del contenuto radiometrico di un dato pixel, a seguito di una trasformazione geometrica. Nell’ambito della fotogrammetria digitale, tale condizioni si verifica spesso, a partire dalla gestione delle stesse immagini. Difatti i software delle stazioni digitali spesso creano delle immagini piramidali, cioè copie rimpicciolite dell’immagine originale, questo per consentirne la veloce visualizzazione in funzione dello zoom utilizzato. In altri termini si limita l’uso della memoria volatile (RAM), evitando di caricare immagini troppo grandi, con un apporto di dettagli che comunque non sarebbero visibili all’utente per quel dato livello di zoom. Si tratta di applicare all’immagine digitale originale un sottocampionamento a fattore fisso, con conseguente riduzione della risoluzione, si ottengono un insieme di immagini derivate aventi però la dimensione del pixel via via crescenti, di un fattore pari all’inverso di quello precedente (Fig. 2.47). Mentre gli algoritmi di autocorrelazione sono utilizzati per aiutare il restitutore nel definire i punti omologhi, oppure per estrarre elementi vettoriali, od ancora, per generare modelli tridimensionali del terreno.
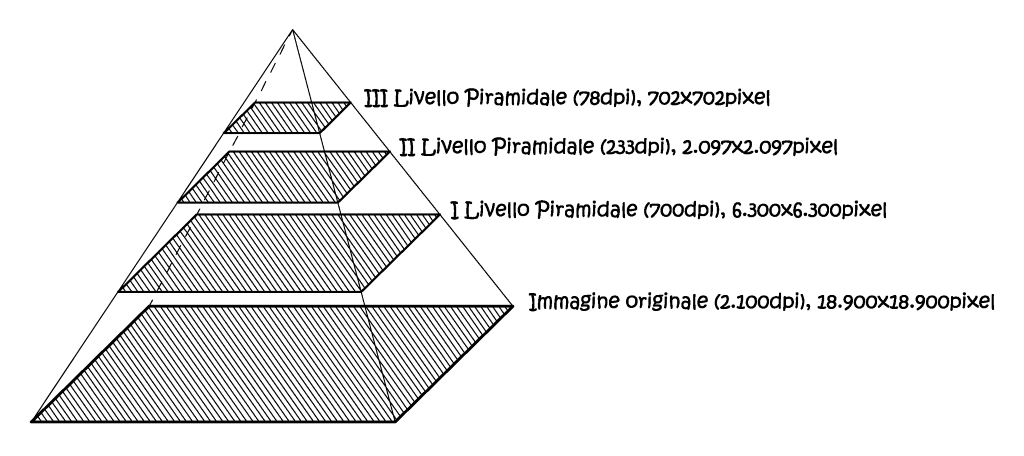
Fig. 2.47 – Esempio di configurazione di un’immagine piramidale.
Il ricampionamento dell’immagine digitale.
Ricampionare un’immagine significa determinare il valore radiometrico di ogni pixel dell’immagine ricampionata, a partire da quella di partenza. In linea del tutto generale, i processi di trasformazione analitica tra due insiemi di dati, possono essere diretti, se è nota la relazione di trasformata, oppure indiretti, qualora la relazione non possa essere nota, oppure non esplicitabile in termini finiti. I metodi di ricampionamento ricadono in questa seconda categoria, quindi si dovranno trovare dei modi di valutazione di influenza pesata del dato iniziale, che si ritiene significativo per la definizione del dato finale, esemplificando, per trovare il nuovo contenuto radiometrico del pixel dell’immagine finale, non si può prescindere dalla valutazione radiometrica dei pixel dell’immagine d’origine (Fig. 2.48).
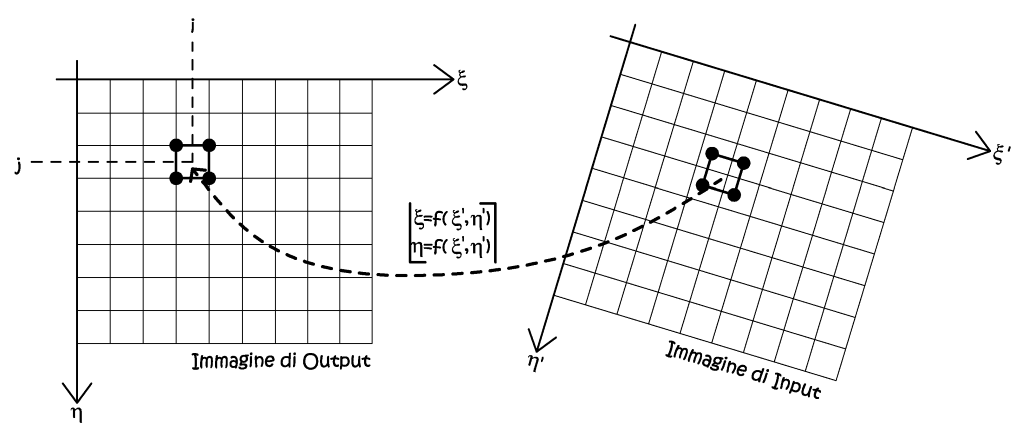
Fig. 2.48 – Il principio del ricampionamento.
In realtà, nella pratica, si parte dall’immagine di output, nota geometricamente, e si operano le trasformazioni inverse, per individuare la posizione dei pixel corrispondenti nell’immagine di input. Il contenuto radiometrico dei pixel di output viene ricavato per interpolazione dei contenuti radiometrici dei pixel di input. Per operare queste trasformazioni è fatto d’obbligo che la funzione di trasformazione f(ξ',η') sia biunivoca, cioè invertibile. I metodi di ricampionamento si dividono in due categorie, nella prima troviamo i metodi del trasporto del baricentro, mentre nella seconda troviamo i metodi di trasporto dei vertici del pixel.
• Trasporto del baricentro.
Tra i metodi del trasporto del baricentro troviamo quello più semplice, cioè il semplice trasporto (Fig. 2.49), si consideri a proposito una semplice trasformazione piana, tra il sistema di riferimento dell’immagine iniziale e quello dell’immagine ricampionata, e supponiamo di conoscerne anche la funzione inversa. Ora possiamo ricavarci le coordinate baricentriche di un qualsiasi pixel, nel sistema dell’immagine d’origine, al quale sarà associato un generico valore radiometrico, in accordo con la sua posizione, e non si opera nessuna altra considerazione.
Questo metodo presenta ottime velocità d’esecuzione, ed i valori radiometrici espressi dalla trasformazione sono tutti identicamente reali, ma è affetto dall’effetto blocking, dato che i baricentri di alcuni pixel dell’immagine ricampionata, una volta trasformati, possono ricadere all’interno del medesimo pixel, dell’immagine iniziale. Ciò comporta la comparsa di gruppi di pixel contigui con il medesimo valore radiometrico.
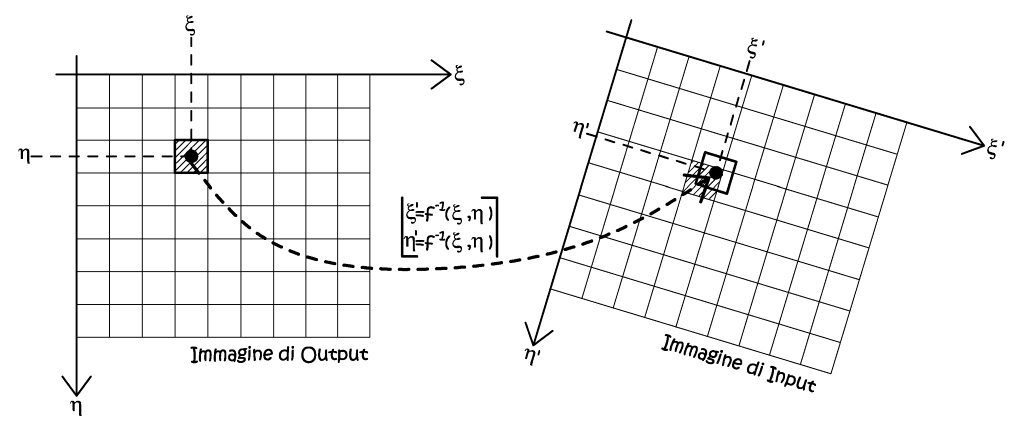
Fig. 2.49 – Il trasporto del baricentro semplice, il contenuto radiometrico assegnato è indipendente dalla posizione del punto baricentrale rispetto agli altri, nell’immagine di Input.
Tale metodo è certamente il più semplice e computazionalmente leggero, ma per risolvere la ripetizione radiometrica di pixel vicini, si devono adottare uno dei seguenti metodi interpolanti, nei quali il valore radiometrico dei pixel adiacenti non viene più ignorato.
• Zone di influenza.
Il pixel viene idealmente scomposto in nove zone (Fig. 2.50) in ragione di un dato valore percentuale, detto soglia di media, esso esprime l’ampiezza delle zone di confine tra i vari pixel adiacenti a quello considerato. Il valore radiometrico assunto dipende dall’area nella quale ricade il punto baricentrico trasformato: se le aree interessate sono quelle mediane, lungo i bordi, il valore sarà la media dei due pixel adiacenti, se il puto di caduta interessa le aree d’angolo, la media sarà espressa da tutti i valori radiometrici dei quattro pixel d’intorno.
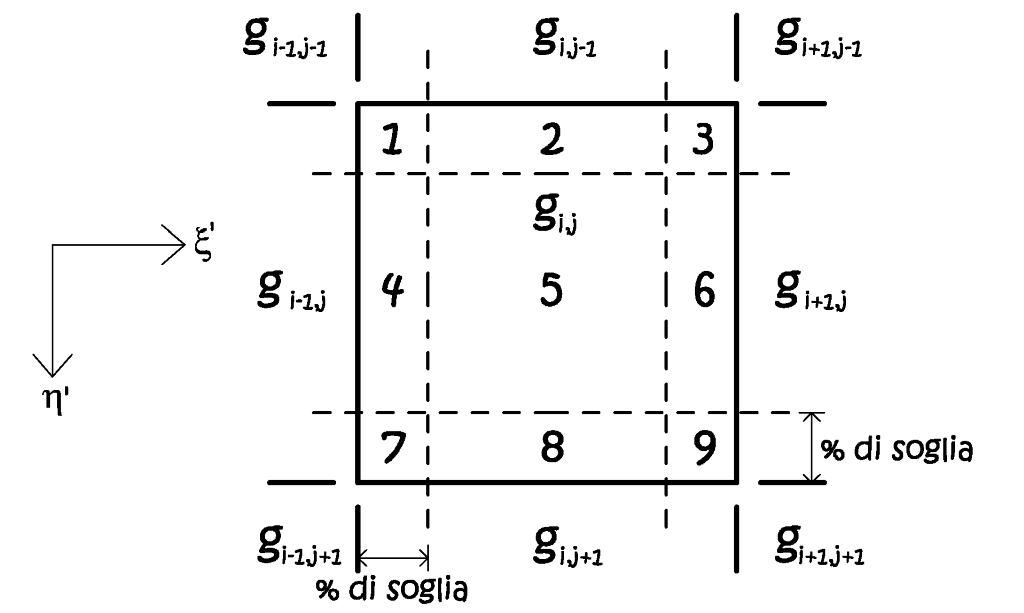
Fig. 2.50 – Ricampionamento per zone d’influenza, con la suddivisione in nove zone.
Se il punto trasformato ricade nell’area interna, cioè nella zona cinque, il valore radiometrico ricampionato è pari al dato radiometrico proprio del pixel g i,j , mentre per tutte le altre zone si hanno valori medi, espressi dalle seguenti:

Per regolare il grado di intervento del filtro, si può agire sulla soglia di media, in ragione delle diverse necessità, ad esempio immagini a bassa risoluzione o a elevato contrasto.
• Metodo delle distanze pesate.
Viene ad essere costruita una griglia passante per i baricentri dei pixel dell’immagine di input, e ad ogni nodo baricentrico viene assegnato il valore radiometrico del pixel di appartenenza. Ora si consideri il generico punto P rappresentante un nodo baricentrico trasformato, ricadente tra i quattro nodi individuati; il valore radiometrico del punto P può essere pensato come la media ponderata sull’inverso delle distanze reciproche, tra il punto ed i nodi di valore radiometrico noto. Quindi il valore radiometrico dei nodi più lontani avrà un minor peso sul valore finale assegnato al punto P.
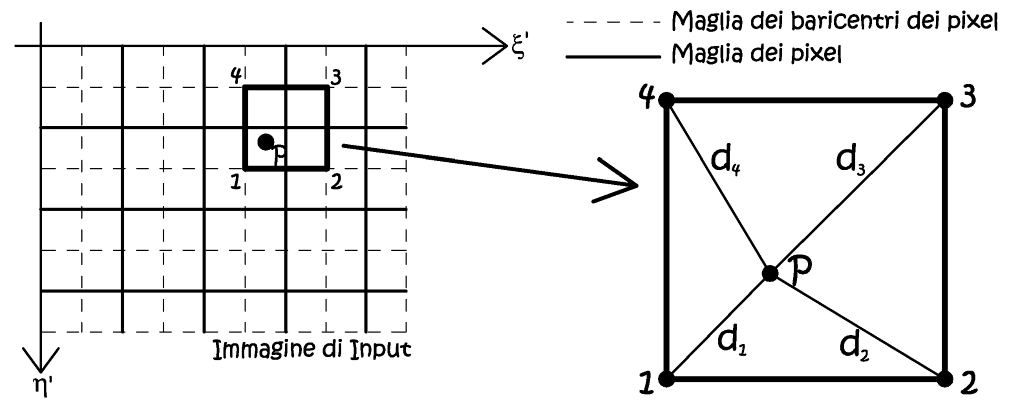
Fig. 2.51 – Ricampionamento con media ponderata sulle distanze.
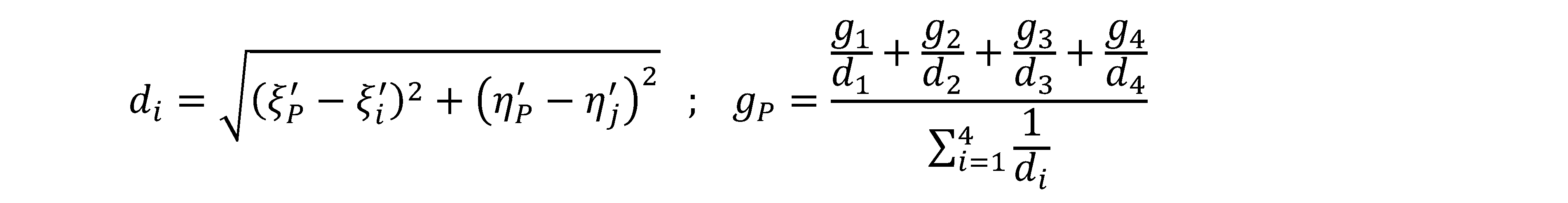
Il peso computazionale di questo metodo è certamente maggiore, rispetto al metodo precedente fornisce un risultato più “morbido” e continuo.
• Interpolazione bilineare.
Qui viene ad essere sfruttata la stessa griglia del metodo precedente, ancora una volta vengono ad essere considerati i valori radiometrici dei nodi più vicini al baricentro trasformato P(ξ',η').
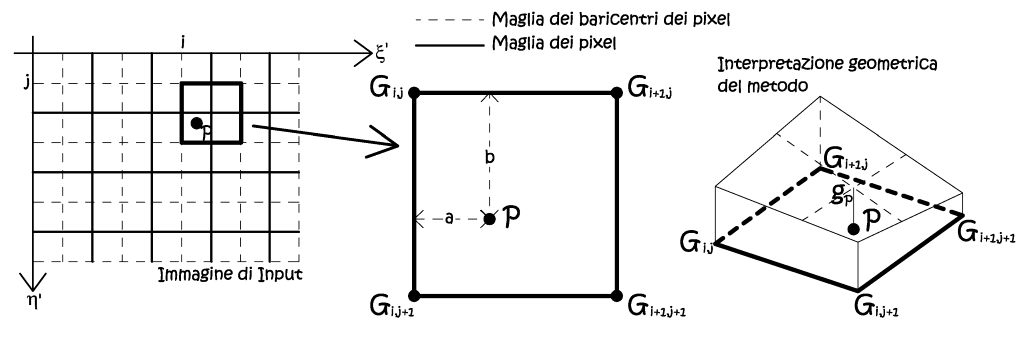
Fig. 2.52 – Ricampionamento per interpolazione lineare.
Il valore cercato appartiene al piano individuato dai valori radiometrici dei nodi baricentrici, si tratta di una media geometrica, data dalla seguente:
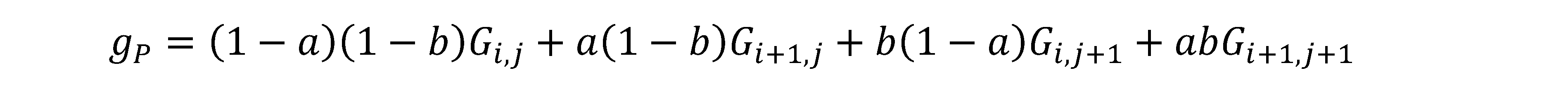
Anche questo metodo fornisce un’immagine ammorbidita, ed i tempi di calcolo sono paragonali al metodo precedente, essendo anche questa un’operazione di media tra quattro valori d’estremità.
• Interpolazione bicubica.
La griglia è sempre la medesima, ma si estende il metodo interpolativo ai sedici nodi più vicini alla posizione del baricentro trasformato nell’immagine di partenza.
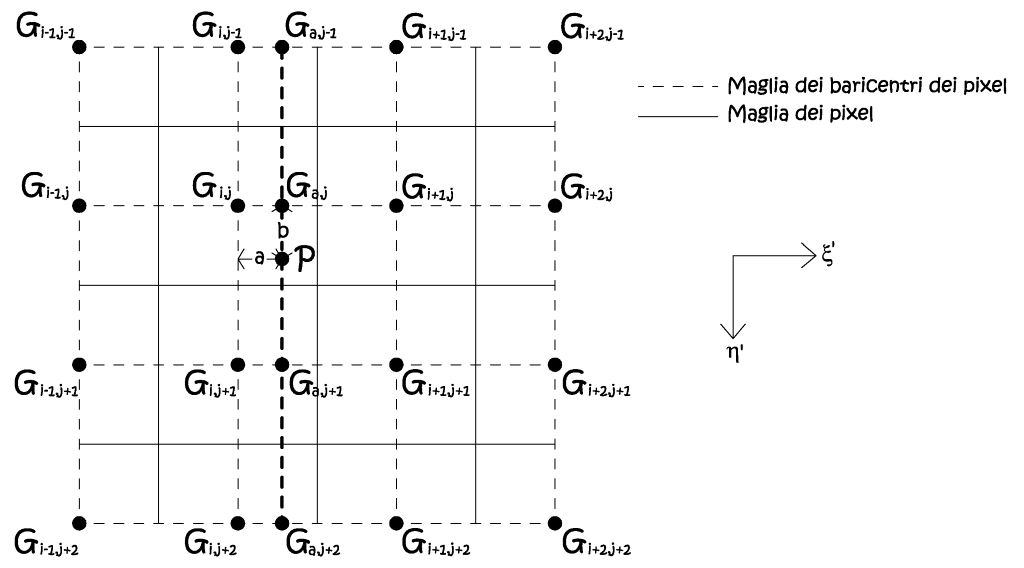
Fig. 2.53 – Ricampionamento per interpolazione bicubica.
La procedura si svolge in due parti distinte; in un primo momento si opera una interpolazione monodimensionale lungo le quattro righe, contenti i valori radiometrici baricentrici, ottenendo quatto valori intermedi allineati lungo la colonna passante per il punto P da interpolare.
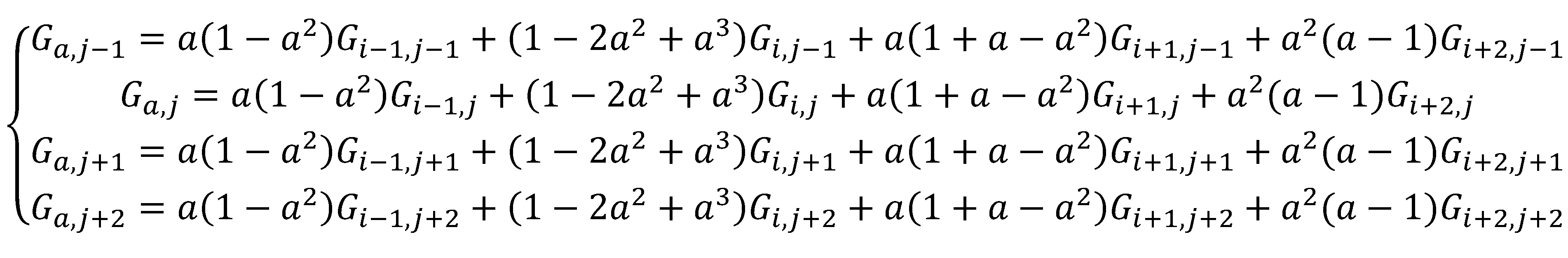
Si osservi come le relazioni appena scritte dipendano solamente da a, ora si interpola monodimensionalmente lungo la colonna passante per il punto P:
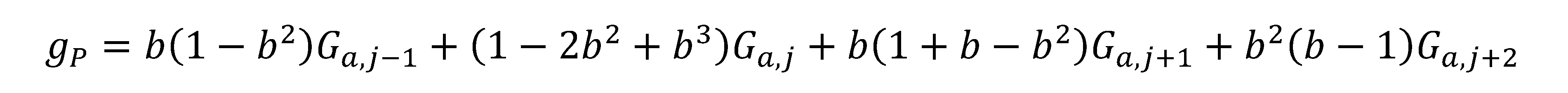
Il metodo presenta una certa complessità di calcolo, che si ripercuote in modo negativo sui tempi macchina, anche in modo considerevole; talvolta la morbidezza delle immagini ottenute appare eccessiva.
• Trasporto dei vertici.
Questo metodo non è molto utilizzato nella fotogrammetria digitale, data la sua pesantezza, avendo come base il calcolo di aree irregolari. Il metodo consiste in una prima fase ove abbiamo il trasporto dei vertici di ogni pixel dell’immagine di output sull’immagine di input, secondo una data trasformazione geometrica. Sull’immagine di partenza (input) i quatto nodi delimitanti la proiezione trasformata del pixel, individueranno una certa porzione areale A, caratterizzata da forma e dimensione variate rispetto a quella del grigliato di partenza. Questa area A si sovrappone e contiene varie porzioni di pixel dell’immagine di input, di ogni singola porzione se ne dovrà ricavare l’estensione superficiale. Il valore radiometrico ricampionato di nuova assegnazione risulterà essere la media pesata dei valori radiometrici delle varie porzioni comprese nell’area A, i pesi non saranno altro che le estensioni delle singole porzioni componenti.
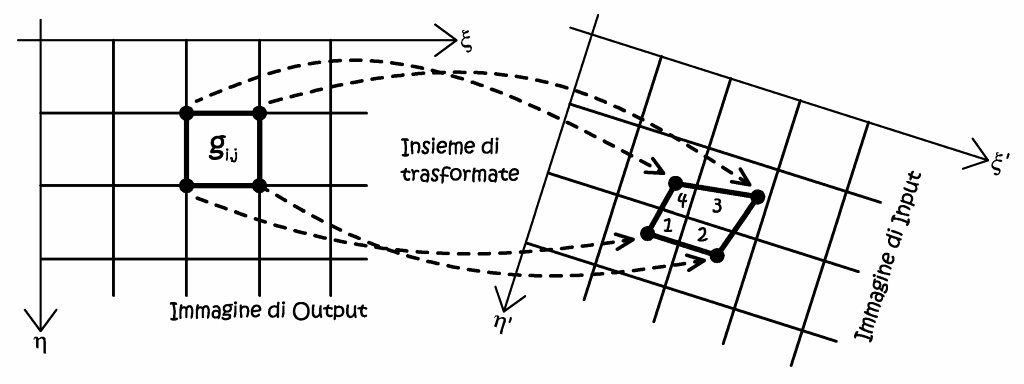
Fig. 2.54 – Principio base del metodo del trasporto dei vertici.
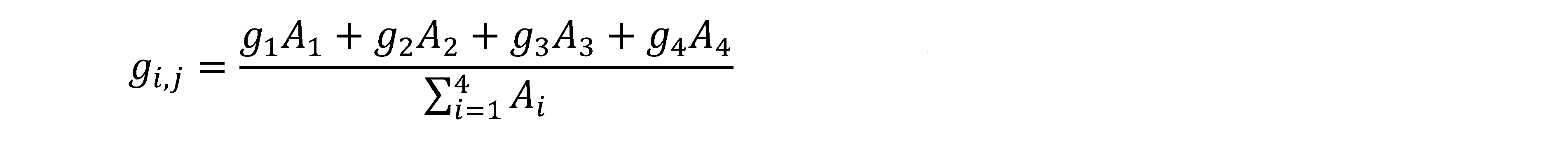
Gli algoritmi di autocorrelazione (image matching).
Le stazioni fotogrammetriche digitali con approccio stereoscopico consentono la generazione di modelli digitali in elevazione del terreno (DTM), questi sono spesso composti anche da milioni di punti, la cui collimazione deve avvenire con procedure automatiche. L’intervento dell’operatore è necessario nelle fasi preparatore al modello stesso, e nella fase di revisione. La tecnica consente l’individuazione e la misura di punti coniugati per via automatica, grazie all’implementazione di opportuni algoritmi, che ora descriveremmo brevemente. Dal punto di vista storico la tecnica dell’image matching non nasce con la fotogrammetria digitale, ma ben prima, negli anni ’50 con i primi tentativi in campo analogico, con l’introduzione di correlatori che mettevano a confronto diversi livelli di grigio. Il primo vero correlatore di respiro commerciale venne introdotto solo a partire dal 1968, dalla Wild, durante un importante congresso. Ma ben presto si comprese che le difficoltà erano notevoli, e dopo vari tentativi, solo in tempi successivi (primi anni ’80) si riuscirono ad introdurre metodi di valenza generale. Il problema era comprendere come la visione umana potesse trovare punti coniugati con estrema facilità, cioè tradurre in relazioni di calcolo i meccanismi dell’interpretazione visiva.
Nelle operazioni di ricerca dei punti coniugati, possiamo scegliere diverse entità di ricerca (entità di matching), che possono essere valori radiometrici, come i livelli di grigio, oppure rappresentazioni astratte e descrizioni simboliche. Appare evidente che in fotogrammetria si utilizza maggiormente il confronto radiometrico, cioè il metodo area-based. Le entità di confronto, nelle due immagini, devono essere messe in correlazione con tecniche che ne valutino la similarità, attraverso l’espressione di una misura quantitativa. Generalmente il grado di similarità si misura con una funzione statistica, che nelle formulazioni più semplici è l’indice di correlazione di Pearson o una valutazione ai minimi quadrati.

Come si è accennato il metodo maggiormente utilizzato in fotogrammetria è l’area-based, mentre gli altri due hanno come entità di matching delle strutture simboliche (punti, linee, regioni, forme), tali metodi sono molto utilizzati in cartografia, o nel recupero della cartografia storica, in questa sede non saranno considerati. In tutti i processi di confronto ci sono due problemi fondamentali, che sono la complessità del calcolo e l’ambiguità, il primo si verifica qualora la misura della similarità viene estesa su tutto il modello, e per tutte le combinazioni possibili, il secondo problema avviene per mancanza di unicità della caratteristica scelta. Appare evidente la necessità di restringere lo spazio di ricerca, difatti la funzione di similarità, che si vuole rendere massima, richiede un certo numero di interazioni, numero che diminuisce con il ridursi dell’area di ricerca intorno alla vera posizione coniugata. Altro modo per ridurre l’indeterminatezza dello spazio di ricerca è di porre dei vincoli geometrici, ad esempio impiegando la ricerca preferenziale utilizzando le immagini piramidali, o i principi di epipolarità, secondo i quali il centro di proiezione, i punti coniugati ed il corrispondente punto oggetto, giacciono tutti sullo stesso piano, il piano epipolare, sempre secondo il dettato di Guido Hauck.
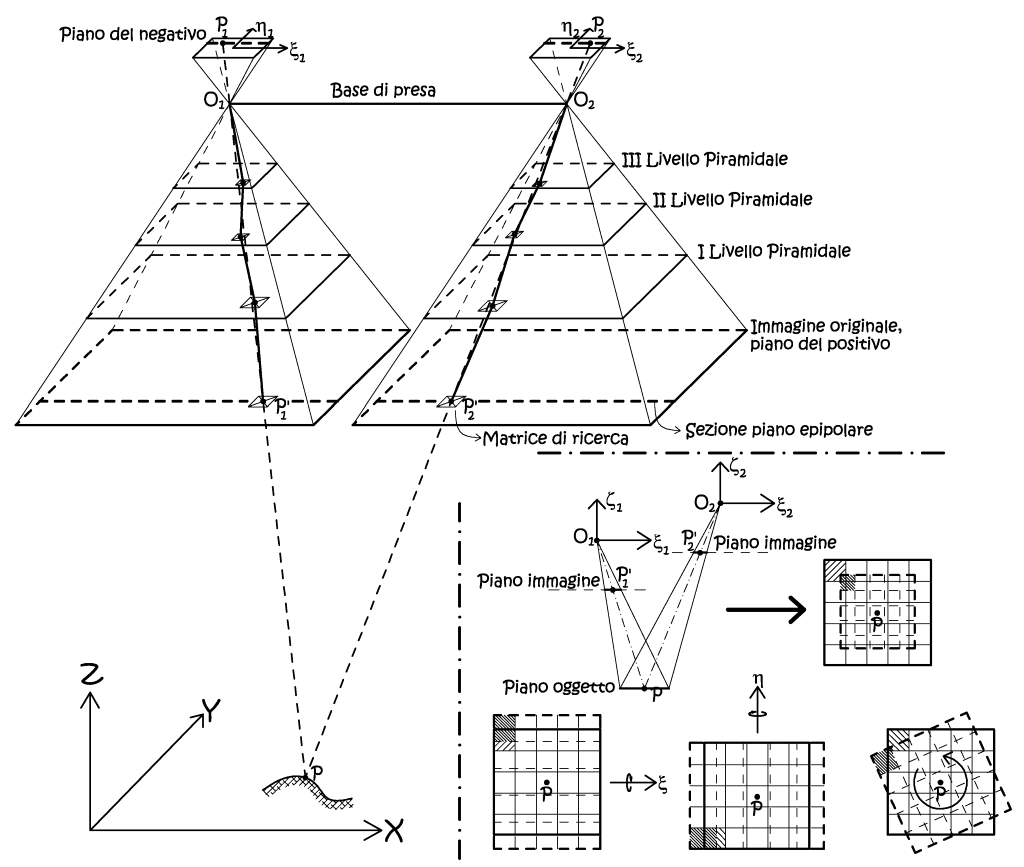
Fig. 2.55 – Utilizzo dei vincoli geometrici (immagini piramidali e piano epipolare) per ridurre l’indeterminatezza dello spazio di ricerca. Il processo di ricerca inizia dall’immagine a minor risoluzione, il risultato ottenuto potrà essere usato nell’immagine successiva, quindi l’algoritmo viene applicato in modo gerarchico. In basso a destra abbiamo la visualizzazione della proiezione sul piano oggetto delle matrici di ricerca coniugate di una stereocoppia con differenti scale immagine, ed effetti della rotazione nei tre assi delle stesse, deformazioni che possono essere trattate con trasformazioni affini.
Come si è anticipato il metodo area-based si fonda sul confronto dei contenuti radiometrici dei pixel, in particolare dei livelli di grigio. Nel processo vengono considerate due aree di confronto, denominate image patches, di cui una rimane fissa in una delle due immagini, mentre l’altra viene mossa all’interno della search window sull’altra immagine, fino a trovare il punto corrispondete in ragione di un criterio di similarità. Tale criterio può essere espresso in due modi, nel primo si utilizza il metodo statistico della massima correlazione, cioè l’indice di Pearson; mentre nel secondo modo si perviene alla minimizzazione dello scarto quadratico medio tra le due image patches.
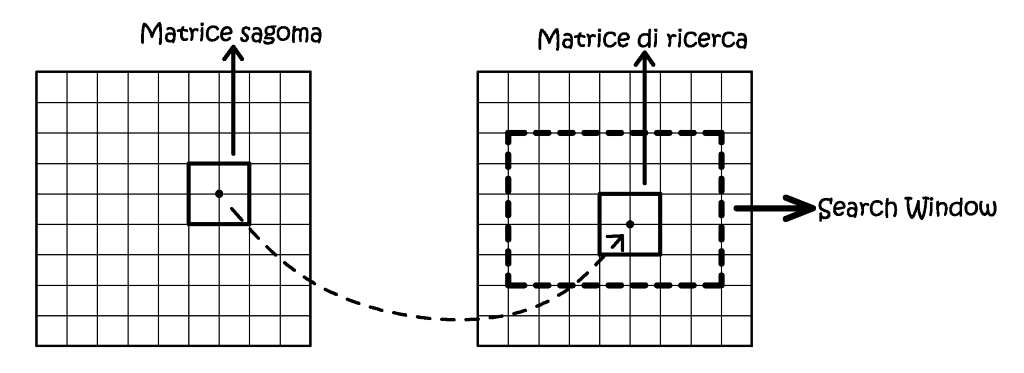
Fig. 2.56 – L’area-based matchi
Il coefficiente di correlazione ρ è espresso dalla seguente:

Dove σ 1 e σ 2 rappresentano le deviazioni standard della densità radiometrica della matrice sagoma e della matrice di ricerca, mentre σ 12 è la loro covarianza. Introducendo le funzioni g 1 (ξ i ,η j ) e g 2 (ξ i ,η j ) della densità radiometrica, le funzioni precedenti possono esprimersi nel modo che segue:
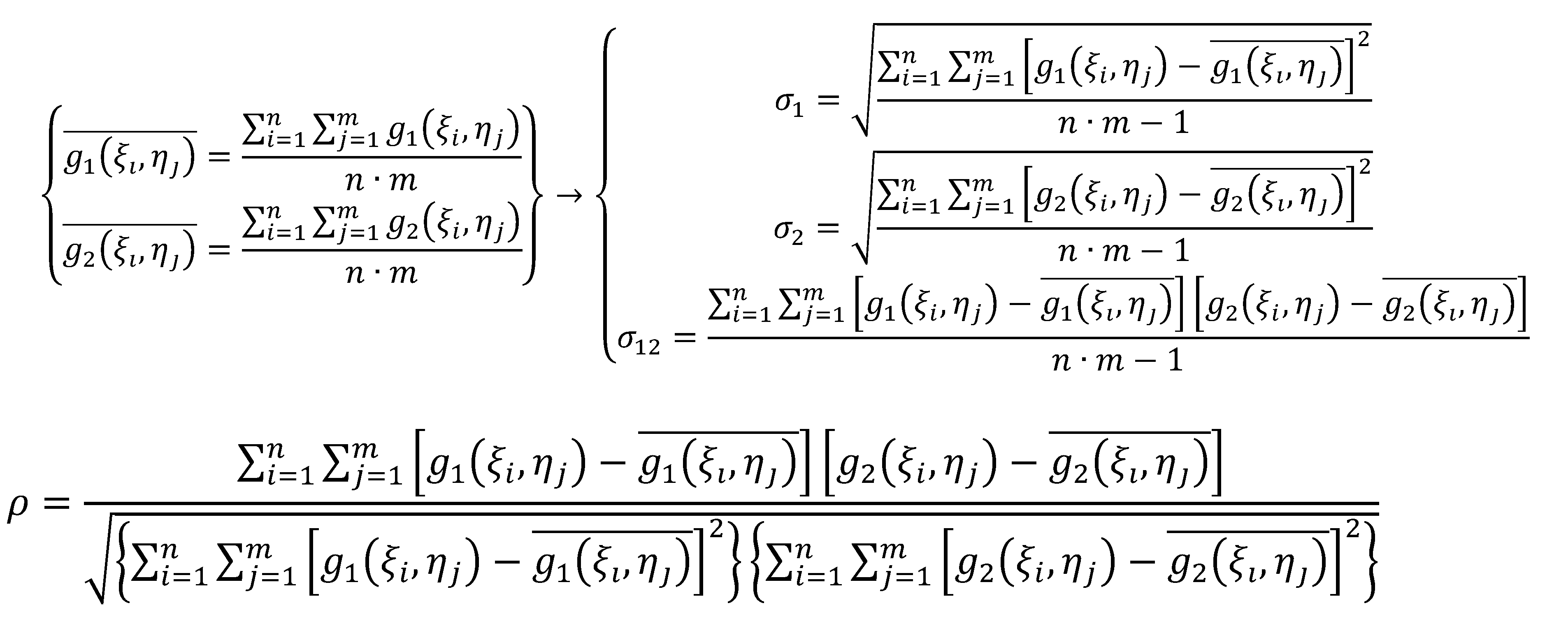
Il valore di correlazione ρ può assumere valori compresi nell’intervallo
±1, il valore ¬+1 lo si ottiene per il caso di perfetta corrispondenza
radiometrica tra le due matrici, il valore opposto (-1) indica una correlazione
inversa, questo potrebbe accadere qualora si confrontasse un’immagine e
la sua negativa. La precisione che è possibile raggiungere con questa tecnica
è limitata alla dimensione del singolo pixel, se si volesse ottenere una
precisione maggiore, si deve utilizzare il secondo metodo, cioè la minimizzazione
dello scarto quadratico medio. Si dovranno considerare anche le distorsioni
radiometriche e le deformazioni geometriche, che comunque saranno sempre
presenti, visto e considerato, che si tratta della presa dello stesso oggetto,
da due punti di vista diversi. È evidente che su queste variazioni possono
solo essere fatte delle ipotesi, ma si è visto che, per piccole aree, si
può considerare una relazione lineare per quanto attiene all’aspetto radiometrico,
ed una trasformazione affine generica per l’ambito geometrico.
Quindi la somiglianza è espressa dalla somma dei quadrati delle differenze
radiometriche a capo di ogni pixel, e la condizione posta è la seguente:
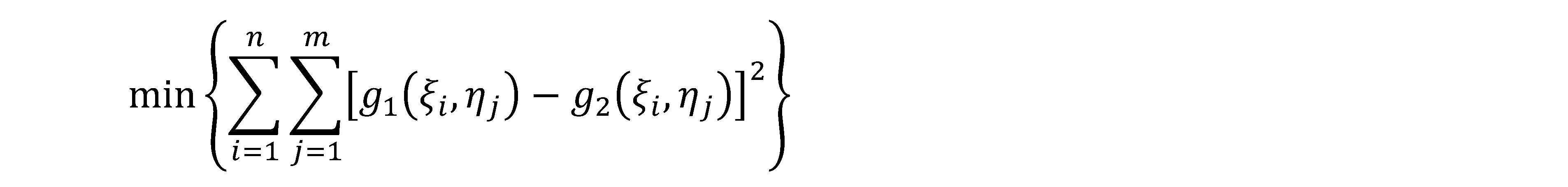
In questa relazione verranno introdotti i parametri afferenti alle caratteristiche radiometriche e geometriche, l’equazione che si ottiene non sarà lineare nei parametri incogniti, la quale dovrà essere linearizzata nell’intorno e risolta per via iterativa. Per garantire la convergenza al sistema si deve partire da dei dati in input sufficientemente approssimati, quindi spesso viene prima eseguito il metodo della correlazione, poi si affronta la minimizzazione degli scarti quadratici. Implementando questo metodo si riesce a migliorare la precisione di un ordine di grandezza, passando dal pixel di incertezza ad una sua frazione.
Lo spazio di ricerca dell’operatore matrice può essere limitato non solo da considerazioni geometriche, o dall’uso delle immagini piramidali, ma anche dall’uso degli operatori di interesse, queste tecniche si basano sul riconoscimento di entità geometricamente rilevanti, come entità lineari o puntuali, e costituisce il metodo che più si avvicini all’interpretazione della visione umana, con le dovute semplificazioni. Da un punto di vista analitico, esemplificando, se si immagina di esprimere le variazioni di densità radiometrica con una superficie esprimibile in termini analitici, si potrà affermare che la sua derivata prima o seconda sia in grado di rappresentare i punti di minimo o di massimo di tale funzione, e la loro natura. Quindi esaltare la presenza di bordi od altre entità ad elevato contrasto radiometrico. Spesso questi algoritmi richiedono la preventiva applicazione di opportuni filtri alle immagini digitali, in modo da ottimizzarne l’operato.
I PRODOTTI DELLA FOTOGRAMMETRIA DIGITALE.
I prodotti della fotogrammetria digitale possono essere dei semplici dati numerici, ad esempio le coordinate di punti oggetto codificate secondo criteri logici, il più semplice modo è quello di utilizzare un file ASCII, ove per ogni riga del file di testo si inseriscono le coordinate puntuali. Ciò è il formato base del DEM, il modello digitale di elevazione, o meglio è uno dei modi di rappresentazione e memorizzazione, ma esso è comunque un database numerico, anche se graficamente può essere interpretato in modo diverso. Ancora oggi i database ASCII di coordinate, costituiscono il modo più veloce di esportare i dati da un’applicazione software ad un’altra.
Poi abbiamo i contenuti vettoriali (si usa il termine shape file in ambito GIS), questi possono essere disegni in genere, oppure la classica restituzione vettoriale al tratto, è questo il modo di indicare tutte quelle entità vettoriali, correttamente georiferite, che il restitutore estrae da un modello stereoscopico, in quest’ambito troviamo le linee costali, confinazioni, viabilità, andamenti fluviali, limiti di processi franosi, ecc. Tutti i programmi in commercio permettono di memorizzare questi contenuti vettoriali secondo gli standard più diffusi del disegno digitale, come il formato .dxf o .dwg. Quindi se oggigiorno i sofisticati algoritmi di correlazione hanno reso semi-automatiche o automatiche molte procedure che un tempo erano manuali, la classica restituzione al tratto viene eseguita manualmente dall’operatore. La restituzione vettoriale può avvenire agendo direttamente nel modello plastico, quindi movendosi in stereoscopia nel modello tridimensionale orientato, ciò è richiesto se le entità da restituire non sono piane, ma si sviluppano nello spazio.
La terza categoria di prodotti vanno sotto il nome di prodotti radiometrici, questi non sono altro che le immagini rettificate, siano esse semplici raddrizzamenti o ortofoto. Il prodotto finale sarà un’immagine geometricamente corretta e georeferenziata, il cui contenuto radiometrico è pari a quello dei frames di partenza, mentre il contenuto metrico è pari a quello di una carta. Quindi le immagini rettificate godono in particolare del vantaggio di unire l’informazione metrica, propria di una cartografia, con quella visiva, propria di una fotografia.
Il modello digitale di elevazione (DEM).
La terza dimensione è stata da sempre rappresentata, sul piano, tramite punti quotati, curve di livello (isoipse) o tinte ipsometriche, quella che in gergo si chiama “tecnica a sfumo”. Oggi i modelli digitali del terreno, o in genere di una qualsiasi superficie, sono composti da una semina di punti collimati con l’uso di tecniche di autocorrelazione, precedentemente esposte, tali punti poi saranno georiferiti con la risoluzione delle equazione della proiettività (equazioni di coolinearità). Con l’acronimo DEM ci si riferisce ad una superficie in genere, mentre con il termine DSM (Digital Surface Model) ci si riferisce alla superficie più elevata in termini altimetrici, quindi nel caso di un territorio essa comprenderà anche tutti gli elementi vegetazionali ed antropici. Con il termine DTM (Digital Terrain Model) si intende la superficie alla quota del suolo, quindi alla superficie al netto di tutti gli elementi su di essa insistenti.
Il modello digitale del terreno può essere ottenuto con tecniche fotogrammetriche, come ora vedremmo, quindi con un metodo di misura indiretto, ma l’evoluzione tecnologica oggi permette l’acquisizione diretta del DTM-DSM, tramite l’impiego della scansione laser con tecnica Lidar. Quindi la generazione dei prodotti fotogrammetrici, quali le ortofoto, può avvenire utilizzando un modello digitale del terreno esterno. I modelli digitali, qualsiasi essi siano, si rappresentano secondo due strutture topologiche diverse, la prima è il TIN (Triangular Irregular Networks) ove i dati sono campionati in modo irregolare, la seconda è il Grid che presenta una struttura a grigliato regolare. Nei TIN i punti di quota nota sono anche i nodi della maglia triangolare utilizzata per l’operazione di meshing della superficie, mentre nel grigliato regolare i punti di quota sono ancora casualmente distribuiti, è evidente che la quota dei nodi della griglia verrà definita da semplici operazioni di interpolazione.
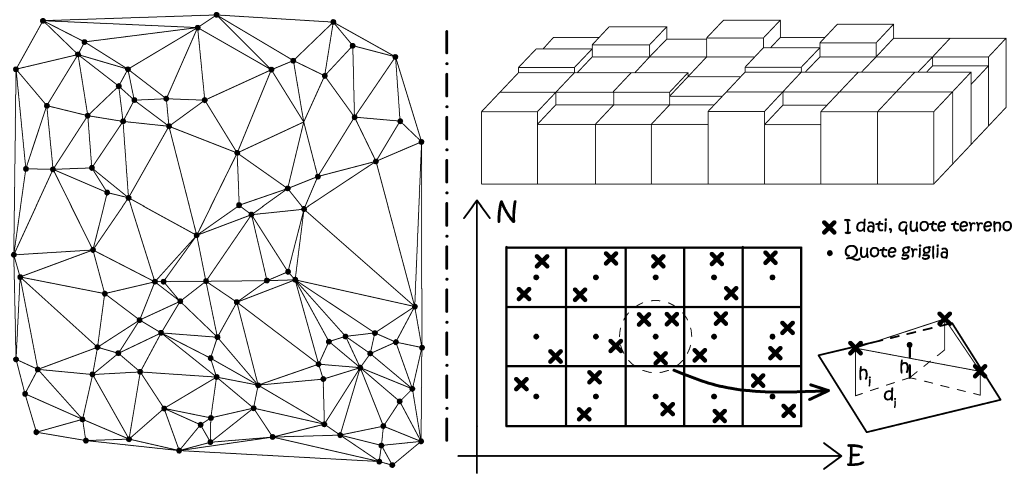
Fig. 2.57 – A sinistra la rappresentazione in pianta di un TIN, i punti di quota note costituiscono i vertici delle varie facce triangolari. A destra un modello Grid, con la tecnica di interpolazione delle quote della griglia.
tecnica lidar.
La tecnica di misura si fonda sulla rilevazione della parte riflessa del raggio laser, dall’analisi di questo impulso di ritorno è possibile determinare la posizione nello spazio della superficie riflettente che lo ha “generato”. La misura della distanza nel sistema Lidar avviene con una misura del tempo di percorso dell’impulso, e in una misura di fase, ovviamente questo permette di conoscere la posizione relativa del punto rispetto alla piattaforma aerea, ma questa ruota e trasla nello spazio in modo continuo, quindi il sistema dovrà essere equipaggiato da un ricevitore GPS a veloce scansione, collegato a terra ad una stazione master, ed un sensore d’assetto inerziale IMU. Dall’integrazione di tutti questi dati GPS/IMU e i dati laser, può essere ricostruito, in sede di post-produzione, il modello digitale del terreno DTM ed il corrispettivo modello lordo DSM. Appare di ogni evidenza il vantaggio di installare affianco al sensore laser una camera digitale metrica, in questo modo utilizzando i dati GPS/IMU ed i dati laser, possiamo risolvere “al volo” il problema dell’orientamento esterno, realizzando il metodo della fotogrammetria diretta. Con i dati radiometrici acquisiti potremmo appore l’opportuna vestizione radiometrica al modello digitale del terreno. Il metodo sembra avere buone prospettive di sviluppo, ma diminuisco i margini di sicurezza all’errore, avendo una minore ridondanza del dato, essendo maggiormente soggetto alle perdite di misura satellitare (cycle splips). Appare evidente che si dovrà curare in modo particolare la fase del progetto e calibrazione del volo. Le precisioni ottenibili sono, ad oggi, simili a quelle ricavabili da buon volo fotogrammetrico classico.
Il modello digitale TIN costituisce il modo più semplice di rappresentare tridimensionalmente il dominio delle misure, intese come dominio delle quote terreno. Il metodo utilizzato è similare a quello adottato per gli elementi finiti, in particolare l’operazione di triangolazione, intesa come vestizione poligonale, utilizza il metodo di Delauney, tale criterio assicura che non ci siano vertici che giacciono dentro l’area di ogni una delle circonferenze circoscritte ai triangoli della rete (Fig. 2.58).
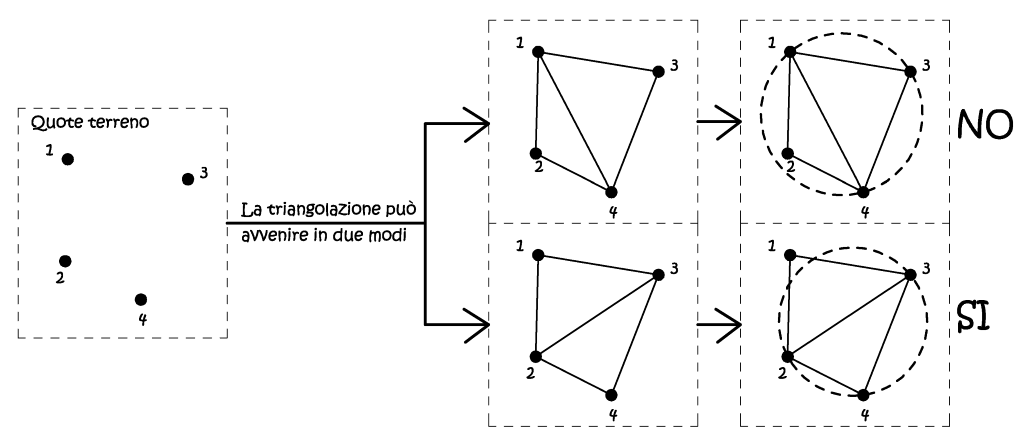
Fig. 2.58 – Il metodo di Delauney nella triangolazione.
Se invece si sceglie di utilizzare il grid come metodo di generazione del nostro DSM, si devono operare delle operazioni di interpolazione, essendo le quote terreno comunque acquisite in modo irregolare, la quota di griglia sarà pari alla media pesata sugli inversi delle distanze dai punti d’appoggio, che saranno compresi entro un raggio massimo di ricerca pari a 1÷1,5 volte il passo griglia (Fig. 2.57):
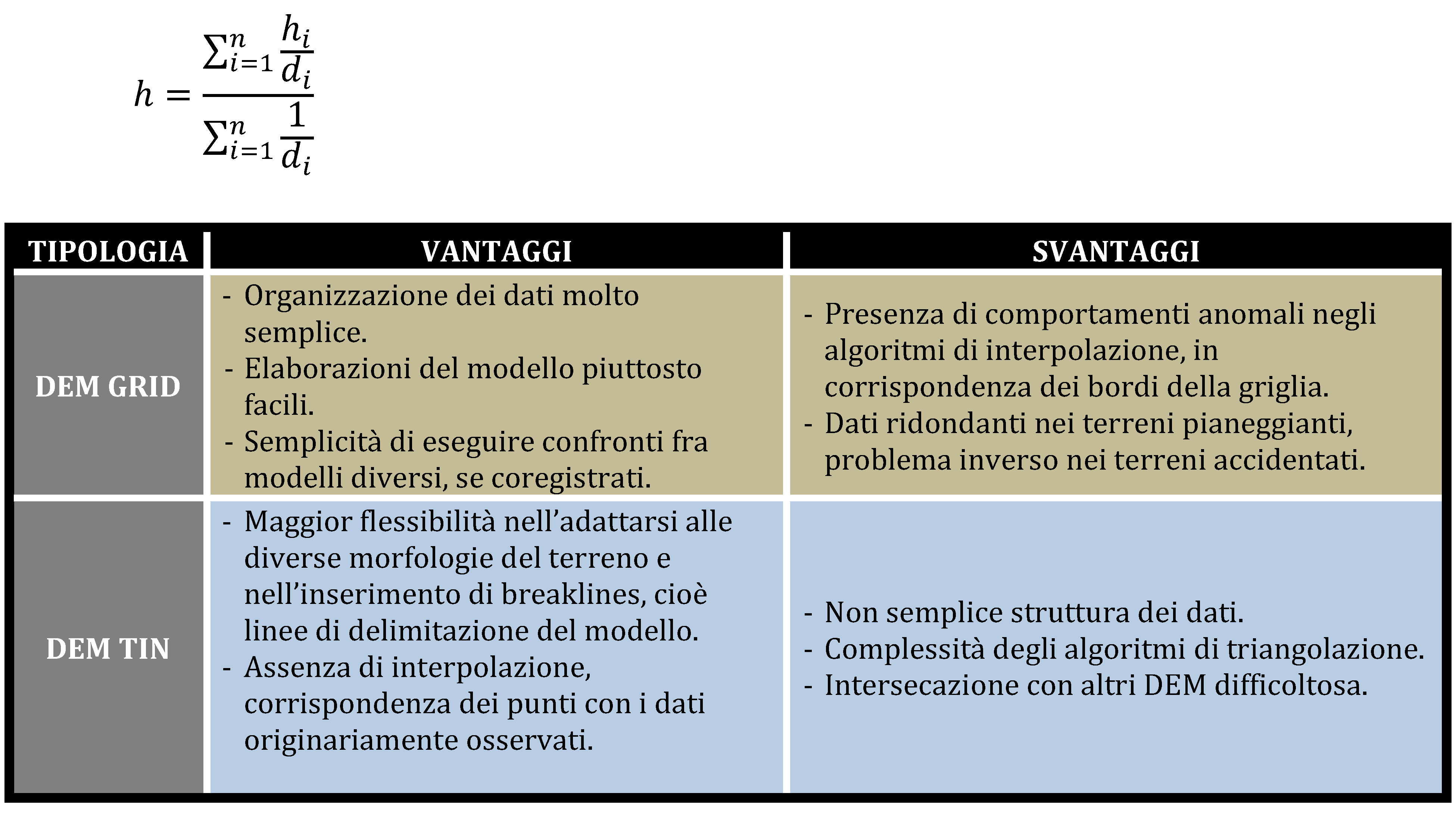
Il modello digitale del terreno costituisce la struttura fondante per tutte le successive analisi o i prodotti da esso derivati, come ad esempio le ortofoto, quindi una sua corretta caratterizzazione è un fattore chiave nella ricostruzione tridimensionale. Difatti nel 2001 il gruppo di lavoro “DTM & Ortofoto” istituito dal Comitato Tecnico di Coordinamento sui Sistemi Informativi Geografici (GIS) dell’Intesa Stato, Regioni, Enti Locali, sotto la direzione del Prof. Otto Kölbl del Politecnico di Losanna, ha redatto un documento sui requisiti e metodi di produzione di modelli digitali del terreno per varie applicazioni, tra cui, come si ricordava, la produzione di ortofoto. In base a queste considerazioni sono state proposte una serie di specifiche per la caratterizzazione di DTM definiti da differenti livelli di precisione, in relazione alle principali applicazioni.
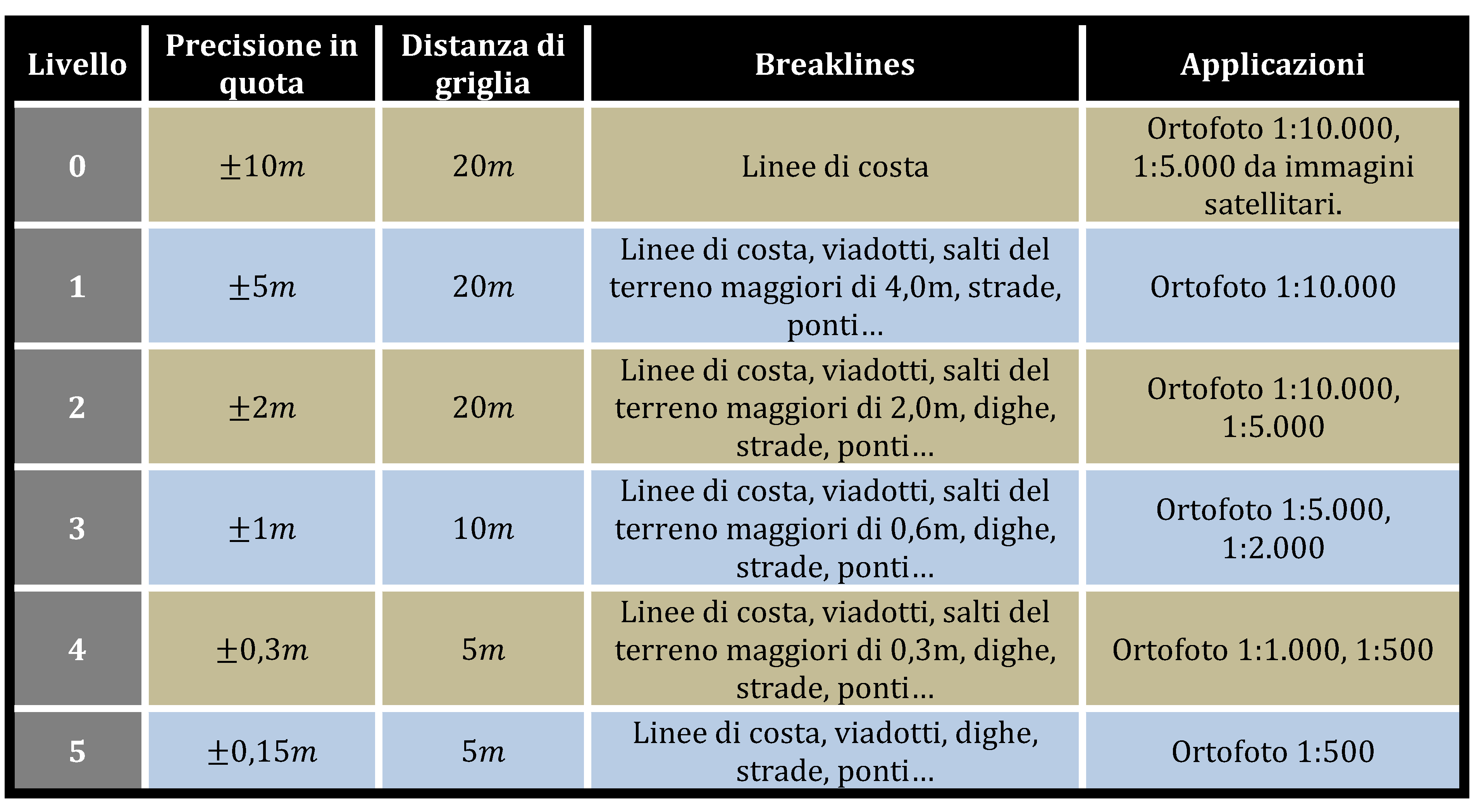
Oggi con l’uso di programmi specialistici si possono ricavare delle carte derivate di calcolo, che esprimono, attraverso l’uso logico di gradienti colorimetrici o entità grafiche, particolari caratteristiche del territorio. Quindi oltre alle definizione delle curve di egual quota, quali sono le isoipse, abbiamo la definizione del gradiente massimo di pendenza (Slope Terrain), oppure l’esposizione (Aspect Terrain), in questo caso si rendono visibili le direzioni cardinali di esposizione. Per il calcolo delle pendenze e dell’esposizione si usano degli appositi algoritmi, che in questa sede tralasciamo, ma si deve ad ogni modo affermare che da un DEM di una certa risoluzione spaziale, non è possibile ottenere una mappa derivata di pari risoluzione. Basti pensare che per ottenere un pixel di dato slope o aspect sono necessarie nove pixel di dato DEM, quindi la risoluzione delle carte di calcolo derivate è minore di quella del DEM di origine. Nelle pagine seguenti sono riportate delle elaborazioni di calcolo ricavati dal DSM del promontorio di Le Castella, lungo la costa ionica calabrese, eseguite con il software specialistico Surfer. Il DSM è costituito da un grid con passo di 5m, per un totale complessivo di oltre due milioni di nodi quotati, ricavato da stazione fotogrammetrica digitale, operante con il software Socet Set, su tre fotogrammi aerei del 1990.
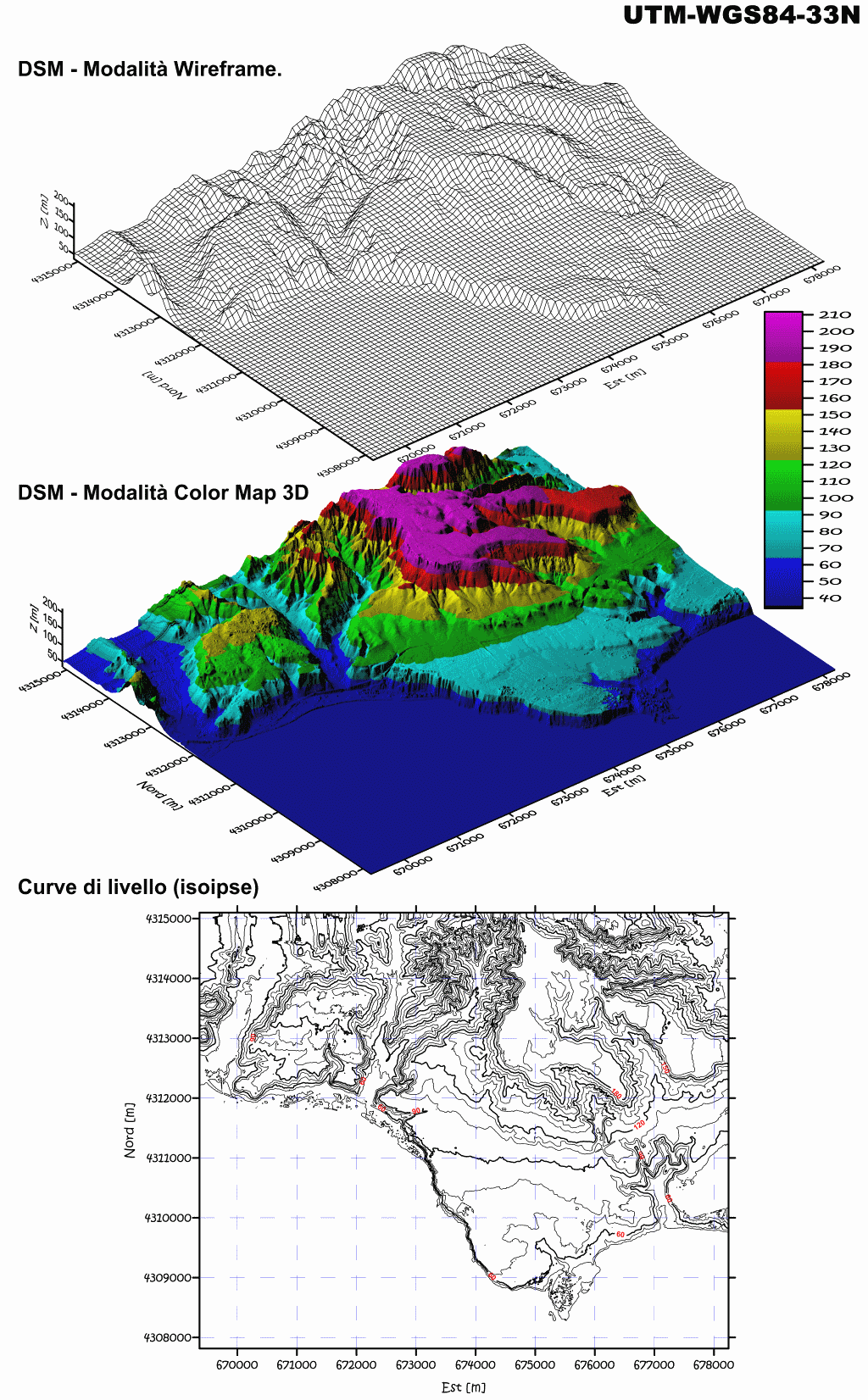
Fig. 2.59 – DSM di Le Castella, posto in varie modalità di visualizzazione. Le quote sono intese espresse in termini ellissoidici, e nei modelli 3D sono amplificate, rispetto alle coordinate piane.
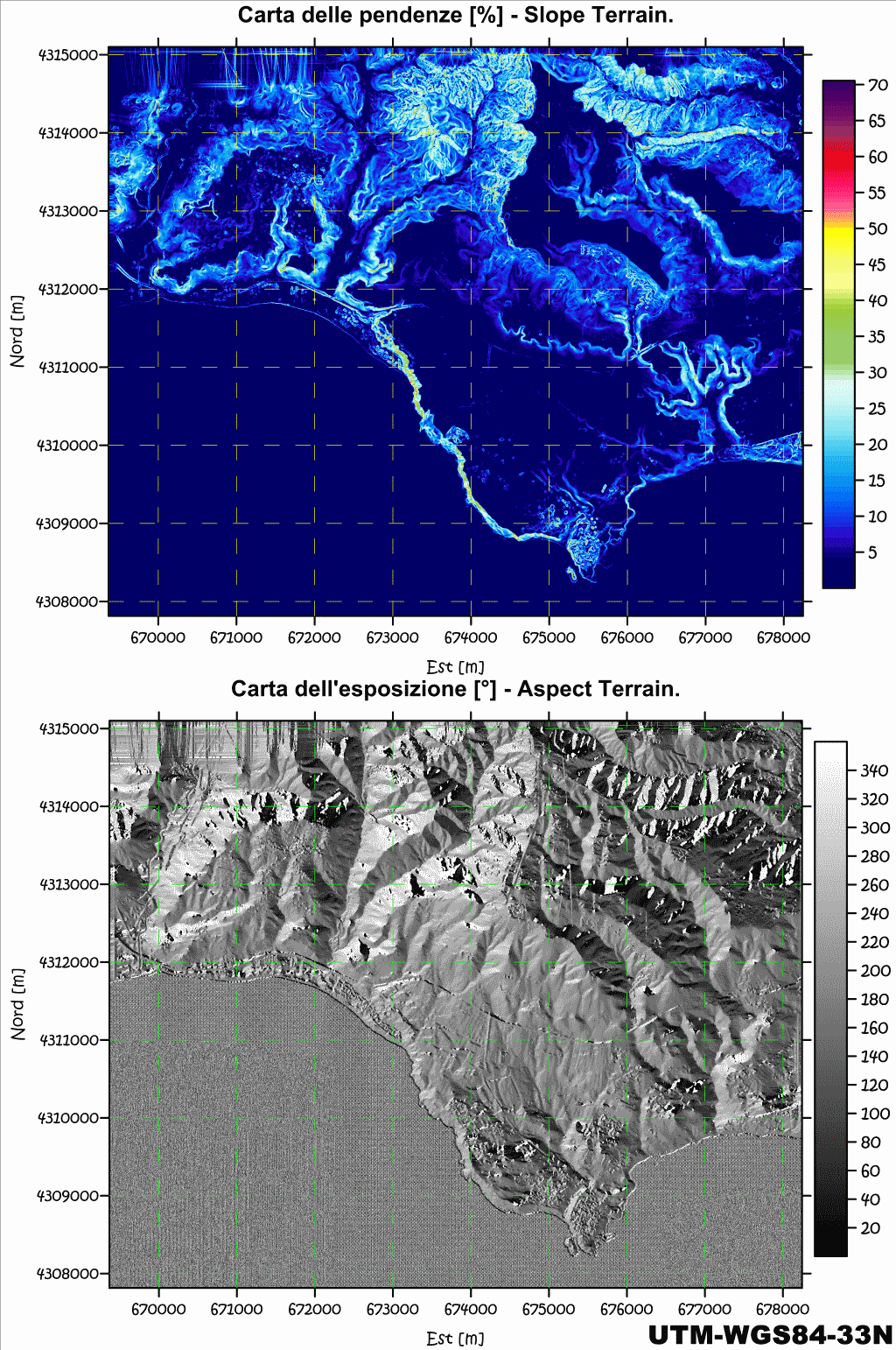
Fig. 2.60 – Due carte di calcolo del medesimo DSM, si noti che nella parte in alto, a sinistra, sono presenti degli artefatti, generati dalla non corretta poligonazione del DSM lungo i suoi confini, limite proprio dei grigliati. Una parte delle coste è costituita da scogliere a strapiombo sul mare, elemento messo subito in risalto dalla carta delle pendenze. Quelli che appaiono essere degli elementi estranei al naturale andamento del suolo, in realtà costituiscono le opere antropiche (quali strade sopraelevate, argini, ed edifici) e le entità vegetazionali, d’altronde questo è un DSM, quindi il modello digitale della prima superficie, quella più in alto, l’unica direttamente visibile nelle fotografie.
Elaborati raster: il raddrizzamento fotogrammetrico.
Si presenta come il modo più semplice di tradurre in termini metrici una riproduzione prospettica fotografica. La condizione cardine da rispettare è che l’oggetto fotografato sia assimilabile ad un piano, oppure che i piccoli scostamenti in quota, se presenti, siano rientranti nelle incertezze di riproduzione cartografica (Fig. 2.61). Spesso questo metodo costituisce l’unica via, qualora non sia possibile ricavare un modello digitale del terreno, che richiede la presenza di stereocopie fotografiche del suolo. Difatti nella fotogrammetria d’archivio, spesso si utilizzano prodotti fotografici non espressamente pensati per la restituzione fotogrammetrica, ne sono un esempio le ricognizioni aeree per fini bellici. La tecnica richiede che il terreno sia pianeggiante, e può essere realizzata anche se l’orientamento interno della camera da presa non è noto.
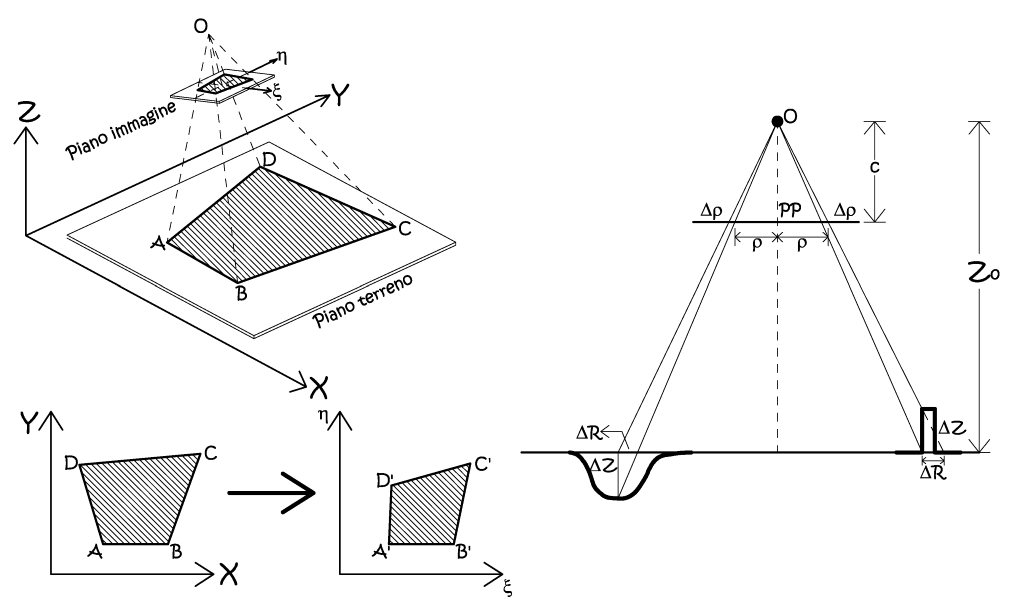
Fig. 2.61 – Il raddrizzamento fotogrammetrico e lo spostamento radiale di oggetti non appartenenti al piano assunto come piano oggetto.
Le immagini dei punti che non giacciono sul piano oggetto, ma si trovano ad una quota ±∆Z, risulteranno spostate di una quantità ±∆ρ in direzione radiale, rispetto al punto principale PP. Lo spostamento radiale, denominato anche errore d’altezza, è dato da semplici relazioni di similitudine:

Dove n è la scala media del fotogramma, appare evidente che questa relazione potrebbe essere usata solamente nel caso di prese perfettamente nadirali, ma può anche essere usata, con buona approssimazione, anche nel caso di prese pseudo-nadirali. Da un punto di vista matematico, la relazione di proiettività che lega le coordinate immagine con le omologhe coordinate oggetto, è una trasformazione nello spazio globale, i cui parametri sono validi per la totalità dei punti dei due domini: lo spazio immagine e lo spazio oggetto. In particolare si tratta di una trasformazione piana ad otto parametri, cioè l’omografia, che definisce una trasformazione di roto-traslazione con variazione anisotropa di scala.

Sono otto parametri da definire, e per ogni punto d’appoggio fotografico (PFA) possiamo scrivere due equazioni di proiettività, quindi ci serviranno come minimo quattro punti. Evidentemente è sempre opportuno, quando possibile, lavorare con un numero di punti superiore allo stretto necessario, poiché solo in tal modo è consentita una valutazione della qualità della trasformazione, ad esempio mediante l’analisi dei residui di una compensazione ai minimi quadrati. L’omografia può essere vista sia sotto l’aspetto analitico, che geometrico, infatti tra i punti del piano oggetto ed i punti del piano immagine intercorrono relazioni geometriche atte a garantire l’uguaglianza dei cosiddetti birappoti, ciò consente di affrontare il raddrizzamento anche solamente individuando le vie di fuga prospettiche delle direttici orizzontali e verticali, metodo molto usato in architettura.
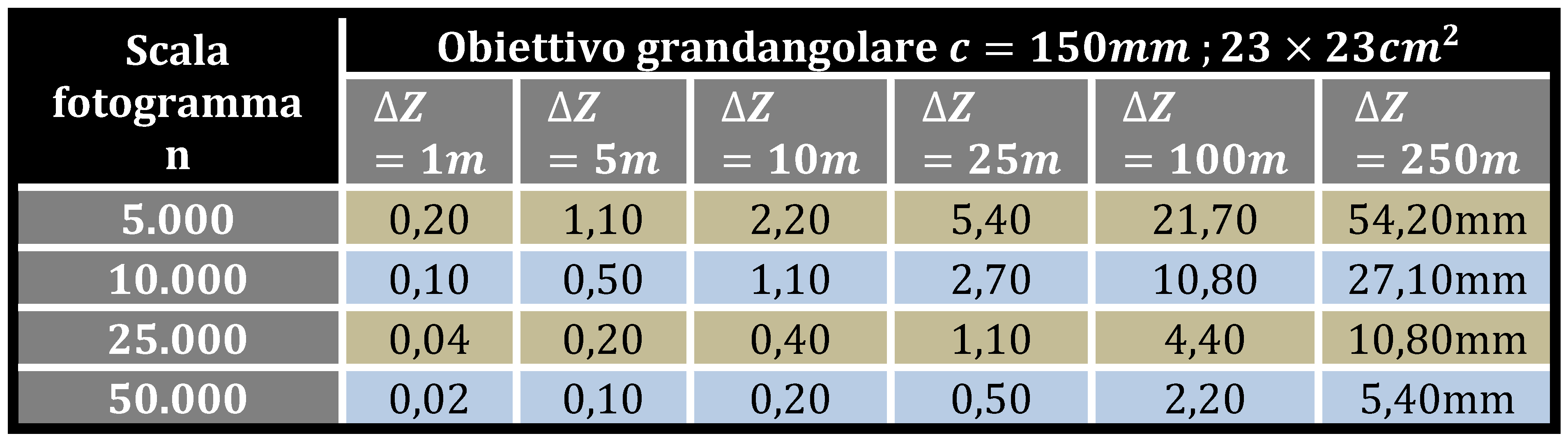
Come si è visto, la condizione necessaria per applicare il raddrizzamento fotogrammetrico è che l’oggetto sia in assimilabile ad un piano, a meno di piccoli scostamenti. Per valutare se gli scostamenti sono trascurabili o meno, si valuta l’errore che si commette nel non considerare la terza dimensione con le relazioni precedenti. Nella tabella che segue sono riportati gli spostamenti radiali in funzione della scala media del fotogramma, nel caso di camera con obiettivo grandangolare, abitualmente utilizzato nella fotogrammetria aerea.
Nella corrente dizione tecnica con il termine fotopiano si intende una mosaicatura di più raddrizzamenti fotogrammetrici, anche se in termini di risultato espresso, nulla cambierebbe se fossero mosaicate delle ortofoto che, come vedremmo, nascono da un metodo radicalmente differente.
Elaborati raster: l'ortofoto.
La trasformazione nello spazio descritta al precedente paragrafo, rientra a pieno titolo tra le trasformazioni globali, dato che i parametri trasformatori sono globalmente validi nei due domini. Ed è ciò vero se gli spazi rappresentano una omografia, ma questo non è più praticabile se le quote del terreno, o meglio la loro reciproca differenza, non è più trascurabile, in ragione alla precisione di restituzione scelta. Se la terza dimensione non può più essere trascurata, si adotta il raddrizzamento differenziale, si tratta di un metodo di generale valenza, ed esso considera delle piccole porzioni di fotogramma che verranno estratte e raddrizzate singolarmente una per una. Nella fotogrammetria digitale le piccole porzioni ortoproiettate coincideranno con i singoli pixel dell’immagine generata. Il prodotto finale sarà un’immagine con il contenuto radiometrico pari a quello dei fotogrammi d’origine (della stereocopia), ed il contenuto metrico di una carta topografica convenzionale. Si può affermare che le ortofoto rappresentino la sintesi dell’incontro di due modi diversi di rappresentare la realtà, modi che costituiscono i pilastri della geometria descrittiva, la proiezione centrale prospettica, e la proiezione ortogonale. Oltre ad utilizzo cartaceo o su supporto digitale, come sono le fotocarte, le immagini ortorettificate trovano naturale impiego nei Sistemi Informativi Territoriali (SIT).
sit&gis
In Italia, nella dizione corrente, spesso di utilizza come sinonimi gli agronomi SIT (Sistemi Informativi Territoriali) e GIS (Sistemi Informativi Geografici). In realtà, come vedremmo, il primo identifica il modo di rappresentare il contenuto geografico, mentre i GIS sono il mezzo software utilizzato a servizio dei SIT.
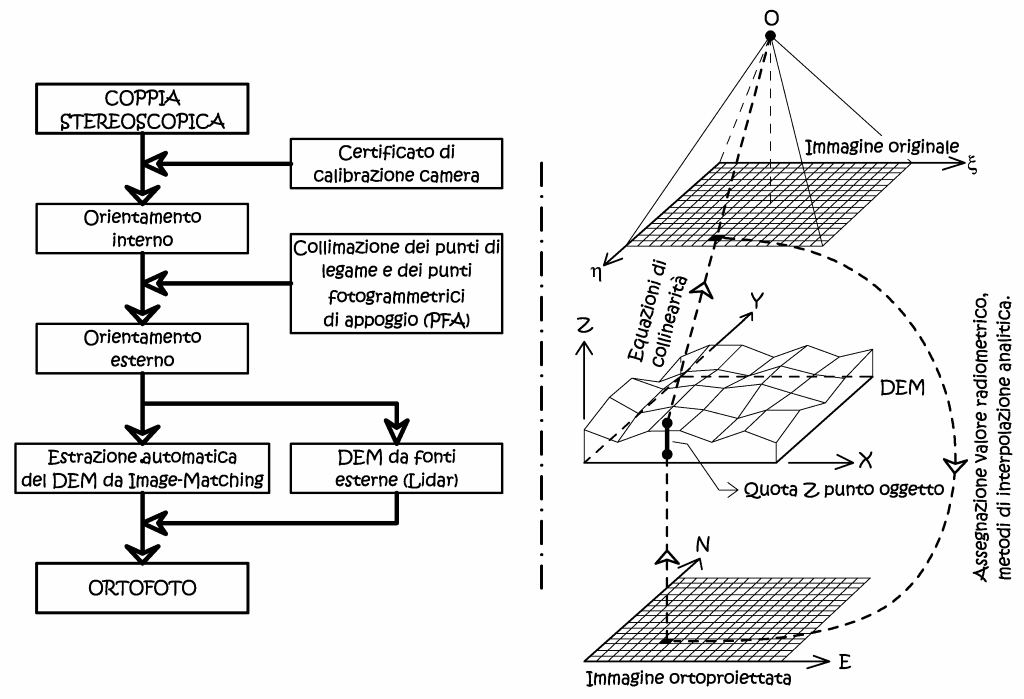
Fig. 2.62 – Generazione di un’ortofoto digitale.
In Fig. 2.62 si può vedere la logica di generazione del prodotto rettificato, si fissa l’area dell’ortoproiezione suddividendola in pixel di opportuna dimensione, di ogni uno di essi vengono determinate le coordinate piane (X,Y), mentre la quota (Z) viene ricavata dal DEM a seguito di interpolazione, dato che questo presenta una risoluzione spaziale usualmente inferiore a quella dell’ortofoto. Le coordinate (X,Y,Z) dello spazio oggetto vengono prospettivizzate utilizzando le equazioni di collinearità, quindi vengono determinate le coordinate immagine (ξ,η). Successivamente grazie alla trasformazione affine di raddrizzamento si ottengono gli indici riga e colonna corrispondenti sull’immagine originale, il valore di densità radiometrica trovata viene assegnata all’immagine rettificata mediante ricampionamento.
Come si può intuire dalla procedura di produzione descritta la qualità metrica dell’ortofoto digitale, dipende dalla qualità del modello di elevazione utilizzato, ovvero dallo scostamento tra l’effettiva superficie fisica e la sua riproduzione analitica. Le considerazioni fatte per il semplice raddrizzamento valgono anche per il raddrizzamento differenziale; tutti gli oggetti che si scostano dalla superficie fisica, oggetto di modellazione, porteranno a degli errori d’altezza, con scostamenti radiali rispetto al punto principale PP. Tali scostamenti andranno valutati in funzione alla precisione, e quindi alla scala, dell’ortofoto. Sempre in riferimento alla Fig. 2.62 si può notare che il processo di ortorettifica potrebbe essere portato a termine con l’uso di una sola immagine d’origine, data che la conoscenza del modello digitale del terreno. Ma ci sono della particolari condizioni operative (Fig. 2.63) ove la necessità di avere una stereocopia è obbligatorio.
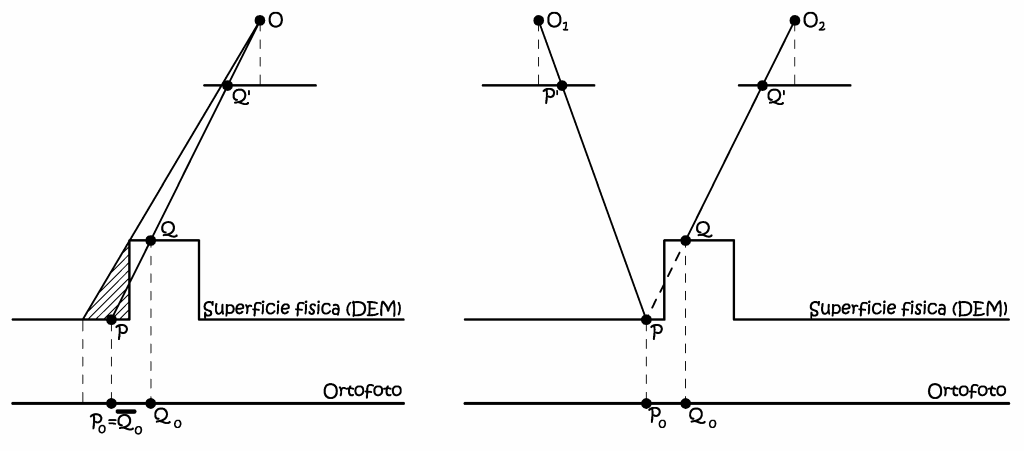
Fig. 2.63 – Il problema delle parti nascoste e il processo di orto-rettifica multi-immagine.
Con una sola immagine avremmo nella zona tratteggiata, un effetto detto di double mapping, in quanto il punto immagine Q' viene rappresentato sull’ortofoto dai punti Q 0 e P 0 . Questo errore può essere eliminato solamente con la procedura di generazione dell’ortofoto di precisione o True Orthophoto, che prevede l’ortorettifica a partire da più immagini, ed è esattamente questo processo che viene usualmente implementato nelle stazioni fotogrammetriche digitali.